在UVM 中所有的驱动都由 sequence 调度 sequencer 进而驱动driver 发出驱动信号
sequence的启动与执行
当完成一个sequence的定义后, 可以使用start任务将其启动
1
2
3
4
5
6
7
|
task case_pwm2duty::main_phase(uvm_phase phase);
pwm_ctrl_sequence pwm_seq;
`uvm_info(get_type_name(), "main_phase is call", UVM_LOW)
pwm_seq = pwm_ctrl_sequence::type_id::create("pwm_seq", this);
pwm_seq.start(env.i_agt.pwm_sqr);
endtask
|
👀 注意: start 后面跟的是 sequencer 的实例
除了直接启动之外, 还可以使用default_sequence启动。 事实上default_sequence会调用start任务, 它有两种调用方式:
一种是比较简洁的方式 :
1
|
uvm_config_db#(uvm_object_wrapper)::set(this, "env.i_agt.sqr.main_phase", "default_sequence", case0_sequence::type_id::get());
|
另外一种方式 是先实例化要启动的sequence, 之后再通过default_sequence启动
1
2
3
4
5
6
7
|
文件: src/ch6/section6.1/6.1.2/my_case0.sv
function void my_case0::build_phase(uvm_phase phase);
case0_sequence cseq;
super.build_phase(phase);
cseq = new("cseq");
uvm_config_db#(uvm_sequence_base)::set(this, "env.i_agt.sqr.main_phase", "default_sequence", cseq);
endfunction
|
当一个sequence启动后会自动执行sequence的body任务。 其实, 除了body外, 还会自动调用sequence的pre_body与post_body
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
文件: src/ch6/section6.1/6.1.2/my_case0.sv
class case0_sequence extends uvm_sequence #(my_transaction);
…
virtual task pre_body();
`uvm_info("sequence0", "pre_body is called!!!", UVM_LOW)
endtask
virtual task post_body();
`uvm_info("sequence0", "post_body is called!!!", UVM_LOW)
endtask
virtual task body();
…
#100;
`uvm_info("sequence0", "body is called!!!", UVM_LOW)
…
endtask
`uvm_object_utils(case0_sequence)
endclass
|
上述代码输出如下:
1
2
3
|
# UVM_INFO my_case0.sv(11) @ 0: uvm_test_top.env.i_agt.sqr@@cseq [sequence0] pre_body is called!!!
# UVM_INFO my_case0.sv(22) @ 100000: uvm_test_top.env.i_agt.sqr@@cseq [sequence0] body is called!!!
# UVM_INFO my_case0.sv(15) @ 100000: uvm_test_top.env.i_agt.sqr@@cseq [sequence0] post_body is called!!!
|
sequence的仲裁机制
在同一sequencer上启动多个sequence
在my_sequencer上同时启动了两个sequence: sequence1和sequence2, 代码如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
文件: src/ch6/section6.2/6.2.1/no_pri/my_case0.sv
task my_case0::main_phase(uvm_phase phase);
sequence0 seq0;
sequence1 seq1;
seq0 = new("seq0");
seq0.starting_phase = phase;
seq1 = new("seq1");
seq1.starting_phase = phase;
fork
seq0.start(env.i_agt.sqr);
seq1.start(env.i_agt.sqr);
join
endtask
|
其中sequence0 定义如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
文件: src/ch6/section6.2/6.2.1/no_pri/my_case0.sv
class sequence0 extends uvm_sequence #(my_transaction);
…
virtual task body();
…
repeat (5) begin
`uvm_do(m_trans)
`uvm_info("sequence0", "send one transaction", UVM_MEDIUM)
end
#100;
…
endtask
`uvm_object_utils(sequence0)
endclass
|
sequence1的定义为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
文件: src/ch6/section6.2/6.2.1/no_pri/my_case0.sv
class sequence1 extends uvm_sequence #(my_transaction);
…
virtual task body();
…
repeat (5) begin
`uvm_do_with(m_trans, {m_trans.pload.size < 500;})
`uvm_info("sequence1", "send one transaction", UVM_MEDIUM)
end
#100;
…
endtask
`uvm_object_utils(sequence1)
endclass
|
运行如上代码后, 会显示两个sequence交替产生transaction:
1
2
3
4
5
6
|
# UVM_INFO my_case0.sv(15) @ 85900: uvm_test_top.env.i_agt.sqr@@seq0 [sequence0] send one transaction
# UVM_INFO my_case0.sv(37) @ 112500: uvm_test_top.env.i_agt.sqr@@seq1 [sequence1] send one transaction
# UVM_INFO my_case0.sv(15) @ 149300: uvm_test_top.env.i_agt.sqr@@seq0 [sequence0] send one transaction
# UVM_INFO my_case0.sv(37) @ 200500: uvm_test_top.env.i_agt.sqr@@seq1 [sequence1] send one transaction
# UVM_INFO my_case0.sv(15) @ 380700: uvm_test_top.env.i_agt.sqr@@seq0 [sequence0] send one transaction
# UVM_INFO my_case0.sv(37) @ 436500: uvm_test_top.env.i_agt.sqr@@seq1 [sequence1] send one transaction
|
sequencer根据什么选择使用哪个sequence的transaction呢? 这是UVM的sequence机制中的仲裁问题。 对于transaction来说, 存在
优先级的概念, 通常来说, 优先级越高越容易被选中。
当使用uvm_do或者uvm_do_with宏时, 产生的transaction的优先级是默认的优先级, 即-1。可以通过uvm_do_pri及uvm_do_pri_with改变所产生的transaction的优先级
uvm_do_pri及uvm_do_pri_with 改变优先级
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
文件: src/ch6/section6.2/6.2.1/item_pri/my_case0.sv
class sequence0 extends uvm_sequence #(my_transaction);
…
virtual task body();
…
repeat (5) begin
`uvm_do_pri(m_trans, 100)
`uvm_info("sequence0", "send one transaction", UVM_MEDIUM)
end
#100;
…
endtask
…
endclass
class sequence1 extends uvm_sequence #(my_transaction);
…
virtual task body();
…
repeat (5) begin
`uvm_do_pri_with(m_trans, 200, {m_trans.pload.size < 500;})
`uvm_info("sequence1", "send one transaction", UVM_MEDIUM)
end
…
endtask
…
endclass
|
uvm_do_pri与uvm_do_pri_with的第二个参数是优先级, 这个数值必须是一个大于等于-1的整数。 数字越大, 优先级越高。
由于sequence1中transaction的优先级较高, 所以按照预期, 先选择sequence1产生的transaction。 当sequence1的transaction全部
生成完毕后, 再产生sequence0的transaction。 但是运行上述代码, 发现并没有如预期的那样, 而是sequence0与sequence1交替产生
transaction。 这是因为sequencer的仲裁算法有很多种:
仲裁(SEQ_ARB)算法
1
2
3
4
5
6
|
SEQ_ARB_FIFO,
SEQ_ARB_WEIGHTED,
SEQ_ARB_RANDOM,
SEQ_ARB_STRICT_FIFO,
SEQ_ARB_STRICT_RANDOM,
SEQ_ARB_USER
|
- SEQ_ARB_FIFO 默认的仲裁算法, 它会严格遵循先入先出的顺序, 而不会考虑优先级。
- SEQ_ARB_WEIGHTED是加权的仲裁;
- SEQ_ARB_RANDOM是完全随机选择;
- SEQ_ARB_STRICT_FIFO是严格按照优先级的,当有多个同一优先级的sequence时, 按照先入先出的顺序选择;
- SEQ_ARB_STRICT_RANDOM是严格按照优先级的, 当有多个同一优先级的sequence时, 随机从最高优先级中选择;
- SEQ_ARB_USER则是用户可以自定义一种新的仲裁算法
设置仲裁(SEQ_ARB)算法
因此, 若想使优先级起作用, 应该设置仲裁算法为SEQ_ARB_STRICT_FIFO或者SEQ_ARB_STRICT_RANDOM
1
2
3
4
5
6
7
8
9
|
文件: src/ch6/section6.2/6.2.1/item_pri/my_case0.sv
task my_case0::main_phase(uvm_phase phase);
…
env.i_agt.sqr.set_arbitration(SEQ_ARB_STRICT_FIFO);
fork
seq0.start(env.i_agt.sqr);
seq1.start(env.i_agt.sqr);
join
endtask
|
经过如上的设置后, 会发现直到sequence1发送完transaction后, sequence0才开始发送
sequence 优先级
sequence 的优先级可以在sequence启动时指定其优先级
1
2
3
4
5
6
7
8
9
|
文件: src/ch6/section6.2/6.2.1/sequence_pri/my_case0.sv
task my_case0::main_phase(uvm_phase phase);
…
env.i_agt.sqr.set_arbitration(SEQ_ARB_STRICT_FIFO);
fork
seq0.start(env.i_agt.sqr, null, 100);
seq1.start(env.i_agt.sqr, null, 200);
join
endtask
|
start任务的第一个参数是sequencer, 第二个参数是parent sequence, 可以设置为null, 第三个参数是优先级, 如果不指定则此值为-1, 它同样不能设置为一个小于-1的数字
数字越大, 优先级越高
对sequence设置优先级的本质即设置其内产生的 transaction的优先级
所以sequence 设置了优先级的话 其内的 transaction 主不用设置优先级了
sequencer的lock操作
所谓lock, 就是sequence向sequencer发送一个请求, 这个请求与其他sequence发送transaction的请求一同被放入sequencer的仲裁
队列中。 当其前面的所有请求被处理完毕后, sequencer就开始响应这个lock请求, 此后sequencer会一直连续发送此sequence的
transaction, 直到unlock操作被调用。 从效果上看, 此sequencer的所有权并没有被所有的sequence共享, 而是被申请lock操作的
sequence独占了。 一个使用lock操作的sequence为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
文件: src/ch6/section6.2/6.2.2/one_lock/my_case0.sv
class sequence1 extends uvm_sequence #(my_transaction);
…
virtual task body();
…
repeat (3) begin
`uvm_do_with(m_trans, {m_trans.pload.size < 500;})
`uvm_info("sequence1", "send one transaction", UVM_MEDIUM)
end
lock();
`uvm_info("sequence1", "locked the sequencer ", UVM_MEDIUM)
repeat (4) begin
`uvm_do_with(m_trans, {m_trans.pload.size < 500;})
`uvm_info("sequence1", "send one transaction", UVM_MEDIUM)
end
`uvm_info("sequence1", "unlocked the sequencer ", UVM_MEDIUM)
unlock();
repeat (3) begin
`uvm_do_with(m_trans, {m_trans.pload.size < 500;})
`uvm_info("sequence1", "send one transaction", UVM_MEDIUM)
end
…
endtask
…
endclass
|
运行例程, 可以发现在lock语句前, sequence0和 seuquence1交替产生transaction;
在lock语句后, 一直发送sequence1的transaction, 直到unlock语句被调用后, sequence0和 seuquence1又开始交替产生transaction。
如果两个sequence都试图使用lock任务来获取sequencer的所有权则会如何呢?
答案是先获得所有权的sequence在执行完毕后才会将所有权交还给另外一个sequence
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
文件: src/ch6/section6.2/6.2.2/dual_lock/my_case0.sv
class sequence0 extends uvm_sequence #(my_transaction);
…
virtual task body();
…
repeat (2) begin
`uvm_do(m_trans)
`uvm_info("sequence0", "send one transaction", UVM_MEDIUM)
end
lock();
repeat (5) begin
`uvm_do(m_trans)
`uvm_info("sequence0", "send one transaction", UVM_MEDIUM)
end
unlock();
repeat (2) begin
`uvm_do(m_trans)
`uvm_info("sequence0", "send one transaction", UVM_MEDIUM)
end
#100;
…
endtask
`uvm_object_utils(sequence0)
endclass
|
运行例程可以发现sequence0先获得sequencer的所有权, 在unlock函数被调用前, 一直发送sequence0的transaction。
在unlock被调用后, sequence1获得sequencer的所有权, 之后一直发送 sequence1的transaction, 直到unlock函数被调用
sequencer的grab操作
与lock操作一样, grab操作也用于暂时拥有sequencer的所有权, 只是grab操作比lock操作优先级更高。
lock请求是被插入sequencer仲裁队列的最后面, 等到它时, 它前面的仲裁请求都已经结束了。
grab请求则被放入sequencer仲裁队列的最前面, 它几乎是一发出就拥有了sequencer的所有权:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
文件: src/ch6/section6.2/6.2.3/my_case0.sv
class sequence1 extends uvm_sequence #(my_transaction);
…
virtual task body();
…
repeat (3) begin
`uvm_do_with(m_trans, {m_trans.pload.size < 500;})
`uvm_info("sequence1", "send one transaction", UVM_MEDIUM)
end
grab();
`uvm_info("sequence1", "grab the sequencer ", UVM_MEDIUM)
repeat (4) begin
`uvm_do_with(m_trans, {m_trans.pload.size < 500;})
`uvm_info("sequence1", "send one transaction", UVM_MEDIUM)
end
`uvm_info("sequence1", "ungrab the sequencer ", UVM_MEDIUM)
ungrab();
repeat (3) begin
`uvm_do_with(m_trans, {m_trans.pload.size < 500;})
`uvm_info("sequence1", "send one transaction", UVM_MEDIUM)
end
…
endtask
`uvm_object_utils(sequence1)
endclass
|
如果两个sequence同时试图使用grab任务获取sequencer的所有权将会如何呢?
这种情况与两个sequence同时试图调用lock函数一样, 在先获得所有权的sequence执行完毕后才会将所有权交还给另外一个试图所有权的sequence。
如果一个sequence在使用grab任务获取sequencer的所有权前, 另外一个sequence已经使用lock任务获得了sequencer的所有权则
会如何呢? 答案是grab任务会一直等待lock的释放。
grab任务还是比较讲文明的, 虽然它会插队, 但是绝不会打断别人正在进行的事情。
sequence的有效性
当有多个sequence同时在一个sequencer上启动时, 所有的sequence都参与仲裁, 根据算法决定哪个sequence发送transaction。 仲
裁算法是由sequencer决定的, sequence除了可以在优先级上进行设置外, 对仲裁的结果无能为力。
通过lock任务和grab任务, sequence可以独占sequencer, 强行使sequencer发送自己产生的transaction。 同样的, UVM也提供措
施使sequence可以在一定时间内不参与仲裁, 即令此sequence失效。
sequencer在仲裁时, 会查看sequence的is_relevant函数的返回结果。 如果为1, 说明此sequence有效, 否则无效。 因此可以通过
重载is_relevant函数来使sequence失效:
重载is_relevant函数来使sequence失效
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
文件: src/ch6/section6.2/6.2.4/is_relevant/my_case0.sv
class sequence0 extends uvm_sequence #(my_transaction);
my_transaction m_trans;
int num;
bit has_delayed;
…
virtual function bit is_relevant();
if((num >= 3)&&(!has_delayed)) return 0;
else return 1;
endfunction
virtual task body();
…
fork
repeat (10) begin
num++;
`uvm_do(m_trans)
`uvm_info("sequence0", "send one transaction", UVM_MEDIUM)
end
while(1) begin
if(!has_delayed) begin
if(num >= 3) begin
`uvm_info("sequence0", "begin to delay", UVM_MEDIUM)
#500000;
has_delayed = 1'b1;
`uvm_info("sequence0", "end delay", UVM_MEDIUM)
break;
end
else
#1000;
end
end
join
…
endtask
…
endclass
|
is_relevant 函数返回1 表示有效, 返回0 表示无效
这个sequence在发送了3个transaction后开始变为无效, 延时500000时间单位后又开始有效。
运行例程会发现在失效前sequence0和sequence1交替发送transaction; 而在失效的500000时间单位内, 只有sequence1发送transaction;
当sequence0重新变有效后, sequence0和sequence1又开始交替发送transaction。 从某种程度上来说, is_relevant与grab 任务和lock任务是完全相反的。
通过设置is_relevant, 可以使sequence主动放弃sequencer的使用权, 而grab任务和lock任务则强占sequencer的所有权
wait_for_relevant
当 sequencer 中所有的 transaction 都发送完毕后才会去执行 wait_for_relevant 函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
文件: src/ch6/section6.2/6.2.4/wait_for_relevant/my_case0.sv
class sequence0 extends uvm_sequence #(my_transaction);
…
virtual function bit is_relevant();
if((num >= 3)&&(!has_delayed)) return 0;
else return 1;
endfunction
virtual task wait_for_relevant();
#10000;
has_delayed = 1;
endtask
virtual task body();
…
repeat (10) begin
num++;
`uvm_do(m_trans)
`uvm_info("sequence0", "send one transaction", UVM_MEDIUM)
end
…
endtask
…
endclass
|
当sequencer发现在其上启动的所有sequence都无效时, 此时会调用wait_for_relevant并等待sequence变有效。
当此sequence与sequence1同时启动, 并发送了3个transaction后, sequence0变为无效。 此后sequencer一直发送sequence1的
transaction, 直到全部的transaction都发送完毕。 此时, sequencer发现sequence0无效, 会调用其wait_for_relevant。 换言之,
sequence0失效是自己控制的, 但是重新变得有效却是受其他sequence的控制。 如果其他sequence永远不结束, 那么sequence0将永
远处于失效状态。
在wait_for_relevant中, 必须将使sequence无效的条件清除。 在代码清单6-20中, 假如wait_for_relevant只是如下定义:
1
2
3
|
virtual task wait_for_relevant();
#10000;
endtask
|
那么当wait_for_relevant返回后, sequencer会继续调用sequence0的is_relevant, 发现依然是无效状态, 则继续调用
wait_for_relevant。 系统会处于死循环的状态。
is_relevant 与 wait_for_relevant 应成对重载
假如在sequence0 重载了 is_relevant, 没有重载 wait_for_relevant, 在sequence0 失效期间如果 sequence1 全部发送完了, sequencer 就会去调用sequence0 的 wait_for_relevant, 此时发现没有重载wait_for_relevant 则会报错
1
|
UVM_FATAL @ 1166700: uvm_test_top.env.i_agt.sqr@@seq0 [RELMSM] is_relevant()was implemented without implemented wait_for_relevant...
|
sequence相关宏及其实现
uvm_do系列宏
uvm_do宏封装了从transaction实例化到发送的一系列操作, 其中包括随机化
uvm_do系列宏主要有以下8个:
1
2
3
4
5
6
7
8
|
`uvm_do(SEQ_OR_ITEM)
`uvm_do_pri(SEQ_OR_ITEM, PRIORITY)
`uvm_do_with(SEQ_OR_ITEM, CONSTRAINTS)
`uvm_do_pri_with(SEQ_OR_ITEM, PRIORITY, CONSTRAINTS)
`uvm_do_on(SEQ_OR_ITEM, SEQR)
`uvm_do_on_pri(SEQ_OR_ITEM, SEQR, PRIORITY)
`uvm_do_on_with(SEQ_OR_ITEM, SEQR, CONSTRAINTS)
`uvm_do_on_pri_with(SEQ_OR_ITEM, SEQR, PRIORITY, CONSTRAINTS)
|
`uvm_do(SEQ_OR_ITEM)
在当前sequencer发送transaction
`uvm_do_pri(SEQ_OR_ITEM, PRIORITY)
在当前sequencer 带优先级的发送transaction
`uvm_do_with(SEQ_OR_ITEM, CONSTRAINTS)
在当前sequencer 带约束的发送transaction
`uvm_do_pri_with(SEQ_OR_ITEM, PRIORITY, CONSTRAINTS)
在当前sequencer 带优先级和约束的发送transaction
uvm_do_on用于显式地指定使用哪个sequencer发送此transaction。
它有两个参数, 第一个是transaction的指针, 第二个是 sequencer的指针。
当在sequence中使用uvm_do等宏时, 其默认的sequencer就是此sequence启动时为其指定的sequencer,
sequence将这个sequencer的指针放在其成员变量m_sequencer中。 事实上, uvm_do等价于:
1
|
`uvm_do_on(tr, this.m_sequencer)
|
`uvm_do_on_pri
它有三个参数, 第一个参数是transaction的指针, 第二个是sequencer的指针, 第三个是优先级:
1
|
`uvm_do_on(tr, this, 100)
|
uvm_do_on_with
它有三个参数, 第一个参数是transaction的指针, 第二个是sequencer的指针, 第三个是约束:
1
|
`uvm_do_on_with(tr, this, {tr.pload.size == 100;})
|
uvm_do_on_pri_with
它有四个参数, 是所有uvm_do宏中参数最多的一个。
第一个参数是transaction的指针,
第二个是sequencer的指针,
第三个是优先级,
第四个是约束
1
|
`uvm_do_on_pri_with(tr, this, 100, {tr.pload.size == 100;})
|
uvm_do系列的其他七个宏其实都是用uvm_do_on_pri_with宏来实现的。 如uvm_do宏:
1
2
|
`define uvm_do(SEQ_OR_ITEM) \
`uvm_do_on_pri_with(SEQ_OR_ITEM, m_sequencer, -1, {})
|
uvm_create与uvm_send
除了使用uvm_do宏产生transaction, 还可以使用uvm_create宏与uvm_send宏来产生:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
文件: src/ch6/section6.3/6.3.2/my_case0.sv
class case0_sequence extends uvm_sequence #(my_transaction);
…
virtual task body();
int num = 0;
int p_sz;
…
repeat (10) begin
num++;
`uvm_create(m_trans)
assert(m_trans.randomize());
p_sz = m_trans.pload.size();
{m_trans.pload[p_sz - 4], m_trans.pload[p_sz - 3], m_trans.pload[p_sz - 2], m_trans.pload[p_sz - 1]} = num;
`uvm_send(m_trans)
end
…
endtask
…
endclass
|
uvm_create宏的作用是实例化transaction。 当一个transaction被实例化后, 可以对其做更多的处理, 处理完毕后使用uvm_send宏
发送出去。 这种使用方式比uvm_do系列宏更加灵活。 如在上例中, 就将pload的最后4个byte替换为此transaction的序号。
事实上, 在上述的代码中, 也完全可以不使用uvm_create宏, 而直接调用new进行实例化:
1
2
3
4
5
6
7
8
9
|
virtual task body();
…
m_trans = new("m_trans");
assert(m_trans.randomize());
p_sz = m_trans.pload.size();
{m_trans.pload[p_sz - 4], m_trans.pload[p_sz - 3], m_trans.pload[p_sz - 2], m_trans.pload[p_sz - 1]} = num;
`uvm_send(m_trans)
…
endtask
|
uvm_send_pri
除了uvm_send外, 还有uvm_send_pri宏, 它的作用是在将transaction交给sequencer时设定优先级:
1
2
3
4
5
6
7
8
9
|
virtual task body();
…
m_trans = new("m_trans");
assert(m_trans.randomize());
p_sz = m_trans.pload.size();
{m_trans.pload[p_sz - 4], m_trans.pload[p_sz - 3], m_trans.pload[p_sz - 2], m_trans.pload[p_sz - 1]} = num;
`uvm_send_pri(m_trans, 200)
…
endtask
|
uvm_rand_send系列宏
uvm_rand_send系列宏有如下几个:
1
2
3
4
|
`uvm_rand_send(SEQ_OR_ITEM)
`uvm_rand_send_pri(SEQ_OR_ITEM, PRIORITY)
`uvm_rand_send_with(SEQ_OR_ITEM, CONSTRAINTS)
`uvm_rand_send_pri_with(SEQ_OR_ITEM, PRIORITY, CONSTRAINTS)
|
uvm_rand_send宏与uvm_send宏类似
唯一的区别是它会对transaction进行随机化。 这个宏使用的前提是transaction已经被分配了空间, 换言之, 即已经实例化了:
1
2
|
m_trans = new("m_trans");
`uvm_rand_send(m_trans)
|
uvm_rand_send_pri宏用于指定transaction的优先级。
它有两个参数, 第一个是transaction的指针, 第二个是优先级:
1
2
|
m_trans = new("m_trans");
`uvm_rand_send_pri(m_trans, 100)
|
uvm_rand_send_with宏, 用于指定使用随机化时的约束,
它有两个参数, 第一个是transaction的指针, 第二个是约束:
1
2
|
m_trans = new("m_trans");
`uvm_rand_send_with(m_trans, {m_trans.pload.size == 100;})
|
uvm_rand_send_pri_with宏, 用于指定优先级和约束,
它有三个参数, 第一个是transaction的指针, 第二个是优先级, 第三个是约束:
1
2
|
m_trans = new("m_trans");
`uvm_rand_send_pri_with(m_trans, 100, {m_trans.pload.size == 100;})
|
uvm_rand_send系列宏及uvm_send系列宏的意义
如果一个transaction占用的内存比较大, 那么很可能希望前后两次发送的transaction都使用同一块内存,
只是其中的内容可以不同, 这样比较节省内存。
start_item与finish_item
不使用宏产生transaction的方式要依赖于两个任务: start_item和finish_item。 在使用这两个任务前, 必须要先实例化transaction
后才可以调用这两个任务:
1
2
3
|
tr = new("tr");
start_item(tr);
finish_item(tr);
|
完整使用如上两个任务构建的一个sequence如下:
1
2
3
4
5
6
7
|
virtual task body();
repeat(10) begin
tr = new("tr");
start_item(tr);
finish_item(tr);
end
endtask
|
上述代码中并没有对tr进行随机化。 可以在transaction实例化后、 finish_item调用前对其进行随机化:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
文件: src/ch6/section6.3/6.3.4/my_case0.sv
class case0_sequence extends uvm_sequence #(my_transaction);
…
virtual task body();
…
repeat (10) begin
tr = new("tr");
assert(tr.randomize() with {tr.pload.size == 200;});
start_item(tr);
finish_item(tr);
end
…
endtask
…
endclass
|
上述assert语句也可以放在start_item之后、 finish_item之前。 uvm_do系列宏其实是将下述动作封装在了一个宏中:
1
2
3
4
5
6
7
8
|
virtual task body();
…
tr = new("tr");
start_item(tr);
assert(tr.randomize() with {tr.pload.size() == 200;});
finish_item(tr);
…
endtask
|
如果要指定transaction的优先级, 那么要在调用start_item和finish_item时都要加入优先级参数:
1
2
3
4
5
6
|
virtual task body();
…
start_item(tr, 100);
finish_item(tr, 100);
…
endtask
|
如果不指定优先级参数, 默认的优先级为-1。
pre_do、 mid_do与post_do
uvm_do宏封装了从transaction实例化到发送的一系列操作, 封装的越多, 则其灵活性越差。 为了增加uvm_do系列宏的功能,
UVM提供了三个接口: pre_do、 mid_do与post_do
- pre_do是一个任务, 在start_item中被调用, 它是start_item返回前执行的最后一行代码, 在它执行完毕后才对transaction进行随机化。
- mid_do是一个函数, 位于finish_item的最开始。 在执行完此函数后, finish_item才进行其他操作。
- post_do也是一个函数, 也位于finish_item中, 它是finish_item返回前执行的最后一行代码。
它们的执行顺序大致为:
1
2
3
4
5
6
7
|
sequencer.wait_for_grant(prior) (task) \ start_item \
parent_seq.pre_do(1) (task) / \
`uvm_do* macros
parent_seq.mid_do(item) (func) \ /
sequencer.send_request(item) (func) \finish_item /
sequencer.wait_for_item_done() (task) /
parent_seq.post_do(item) (func) /
|
wait_for_grant、 send_request及wait_for_item_done都是UVM内部的一些接口。
pre_do mid_do post_do 这三个接口函数/任务的使用示例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
文件: src/ch6/section6.3/6.3.5/my_case0.sv
class case0_sequence extends uvm_sequence #(my_transaction);
my_transaction m_trans;
int num;
…
virtual task pre_do(bit is_item);
#100;
`uvm_info("sequence0", "this is pre_do", UVM_MEDIUM)
endtask
virtual function void mid_do(uvm_sequence_item this_item);
my_transaction tr;
int p_sz;
`uvm_info("sequence0", "this is mid_do", UVM_MEDIUM)
void'($cast(tr, this_item));
p_sz = tr.pload.size();
{tr.pload[p_sz - 4], tr.pload[p_sz - 3], tr.pload[p_sz - 2], tr.pload[p_sz - 1]} = num;
tr.crc = tr.calc_crc();
tr.print();
endfunction
virtual function void post_do(uvm_sequence_item this_item);
`uvm_info("sequence0", "this is post_do", UVM_MEDIUM)
endfunction
virtual task body();
…
repeat (10) begin
num++;
`uvm_do(m_trans)
end
…
endtask
…
endclass
|
pre_do有一个参数, 此参数用于表明uvm_do宏是在对一个transaction还是在对一个sequence进行操作, 关于这一点请参考6.4.1 节。
mid_do和post_do的两个参数是正在操作的sequence或者item的指针, 但是其类型是uvm_sequence_item类型。 通过cast可以转换
成目标类型( 示例中为my_transaction)
sequence进阶应用
嵌套的sequence
假设一个产生CRC错误包的sequence如下:
1
2
3
4
5
6
7
8
|
文件: src/ch6/section6.4/6.4.1/start/my_case0.sv
class crc_seq extends uvm_sequence#(my_transaction);
…
virtual task body();
my_transaction tr;
`uvm_do_with(tr, {tr.crc_err == 1; tr.dmac == 48'h980F;})
endtask
endclass
|
另外一个产生长包的sequence如下:
1
2
3
4
5
6
7
8
|
文件: src/ch6/section6.4/6.4.1/start/my_case0.sv
class long_seq extends uvm_sequence#(my_transaction);
…
virtual task body();
my_transaction tr;
`uvm_do_with(tr, {tr.crc_err == 0; tr.pload.size() == 1500; tr.dmac == 48'hF675;})
endtask
endclass
|
现在要写一个新的sequence, 它可以交替产生上面的两种包。 那么在新的sequence里面可以这样写:
1
2
3
4
5
6
7
8
9
|
class case0_sequence extends uvm_sequence #(my_transaction);
virtual task body();
my_transaction tr;
repeat (10) begin
`uvm_do_with(tr, {tr.crc_err == 1; tr.dmac == 48'h980F;})
`uvm_do_with(tr, {tr.crc_err == 0; tr.pload.size() == 1500; tr.dmac == 48'hF675;})
end
endtask
endclass
|
似乎这样写起来显得特别麻烦。 产生的两种不同的包中, 第一个约束条件有两个, 第二个约束条件有三个。 但是假如约束条
件有十个呢? 如果整个验证平台中有30个测试用例都用到这样的两种包, 那就要在这30个测试用例的sequence中加入这些代码,
这是一件相当恐怖的事情, 而且特别容易出错。 既然已经定义好crc_seq和long_seq, 那么有没有简单的方法呢? 答案是肯定的。
在一个sequence的body中, 除了可以使用uvm_do宏产生transaction外, 其实还可以启动其他的sequence, 即一个sequence内启动另
外一个sequence, 这就是嵌套的sequence:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
文件: src/ch6/section6.4/6.4.1/start/my_case0.sv
class case0_sequence extends uvm_sequence #(my_transaction);
…
virtual task body();
crc_seq cseq;
long_seq lseq;
…
repeat (10) begin
cseq = new("cseq");
cseq.start(m_sequencer);
lseq = new("lseq");
lseq.start(m_sequencer);
end
…
endtask
…
endclass
|
直接在新的sequence的body中调用定义好的sequence, 从而实现sequence的重用。 这个功能是非常强大的。 在上面代码中,
m_sequencer是case0_sequence在启动后所使用的sequencer的指针。 但通常来说并不用这么麻烦, 可以使用uvm_do宏来完成这些事情:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
文件: src/ch6/section6.4/6.4.1/uvm_do/my_case0.sv
class case0_sequence extends uvm_sequence #(my_transaction);
…
virtual task body();
crc_seq cseq;
long_seq lseq;
…
repeat (10) begin
`uvm_do(cseq)
`uvm_do(lseq)
end
…
endtask
…
endclass
|
uvm_do系列宏中, 其第一个参数除了可以是transaction的指针外, 还可以是某个sequence的指针。 当第一个参数是transaction
时, 它如6.3.4节代码清单6-39中所示, 调用start_item和finish_item; 当第一个参数是sequence时, 它调用此sequence的start任务。
除了uvm_do宏外, 前面介绍的uvm_send宏、 uvm_rand_send宏、 uvm_create宏, 其第一个参数都可以是sequence的指针。 唯一
例外的是start_item与finish_item, 这两个任务的参数必须是transaction的指针。
在sequence中使用rand类型变量
在transaction的定义中, 通常使用rand来对变量进行修饰, 说明在调用randomize时要对此字段进行随机化。 其实在sequence中
也可以使用rand修饰符。 有如下的sequence, 它有成员变量ldmac:
1
2
3
4
5
6
7
8
9
10
|
文件: src/ch6/section6.4/6.4.2/rand/my_case0.sv
class long_seq extends uvm_sequence#(my_transaction);
rand bit[47:0] ldmac;
…
virtual task body();
my_transaction tr;
`uvm_do_with(tr, {tr.crc_err == 0; tr.pload.size() == 1500; tr.dmac == ldmac;})
tr.print();
endtask
endclass
|
这个sequence可以作为底层的sequence被顶层的sequence调用:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
文件: src/ch6/section6.4/6.4.2/rand/my_case0.sv
class case0_sequence extends uvm_sequence #(my_transaction);
…
virtual task body();
long_seq lseq;
…
repeat (10) begin
`uvm_do_with(lseq, {lseq.ldmac == 48'hFFFF;})
end
…
endtask
…
endclass
|
sequence里可以添加任意多的rand修饰符, 用以规范它产生的transaction。 sequence与transaction都可以调用randomize进行随机
化, 都可以有rand修饰符的成员变量, 从某种程度上来说, 二者的界限比较模糊。 这也就是为什么uvm_do系列宏可以接受 sequence作为其参数的原因。
在sequence中定义rand类型变量时, 要注意变量的命名。 很多人习惯于变量的名字和transaction中相应字段的名字一致:
1
2
3
4
5
6
7
8
9
10
|
文件: src/ch6/section6.4/6.4.2/name/my_case0.sv
class long_seq extends uvm_sequence#(my_transaction);
rand bit[47:0] dmac;
…
virtual task body();
my_transaction tr;
`uvm_do_with(tr, {tr.crc_err == 0; tr.pload.size() == 1500; tr.dmac == dmac;})
tr.print();
endtask
endclass
|
在case0_sequence中启动上述sequence, 并将dmac地址约束为48’hFFFF, 此时将会发现产生的transaction的dmac并不是
48‘hFFFF, 而是一个随机值! 这是因为, 当运行到上述代码的第15行时, 编译器会首先去my_transaction寻找dmac, 如果找到了,
就不再继续寻找。 换言之, 上述代码第13到第15行等价于:
1
|
`uvm_do_with(tr, {tr.crc_err == 0; tr.pload.size() == 1500; tr.dmac == tr.dmac;})
|
long_seq中的dmac并没有起到作用。 所以, 在sequence中定义rand类型变量以向产生的transaction传递约束时, 变量的名字一定
要与transaction中相应字段的名字不同。
transaction类型的匹配, 使用 $cast 转换
一个sequencer只能产生一种类型的transaction, 一个sequence如果要想在此sequencer上启动,
那么其所产生的transaction的类型必须是这种transaction或者派生自这种transaction
如果一个sequence中产生的transaction的类型不是此种transaction, 那么将会报错:
1
2
3
4
5
6
7
8
|
class case0_sequence extends uvm_sequence #(my_transaction);
your_transaction y_trans;
virtual task body();
repeat (10) begin
`uvm_do(y_trans)
end
endtask
endclass
|
嵌套sequence的前提是, 在套里面的所有sequence产生的transaction都可以被同一个sequencer所接受。
那么有没有办法将两个截然不同的transaction交给同一个sequencer呢? 可以, 只是需要将sequencer和driver能够接受的数据类
型设置为uvm_sequence_item:
1
2
|
class my_sequencer extends uvm_sequencer #(uvm_sequence_item);
class my_driver extends uvm_driver#(uvm_sequence_item);
|
在sequence中可以交替发送my_transaction和your_transaction:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
文件: src/ch6/section6.4/6.4.3/my_case0.sv
class case0_sequence extends uvm_sequence;
my_transaction m_trans;
your_transaction y_trans;
…
virtual task body();
…
repeat (10) begin
`uvm_do(m_trans)
`uvm_do(y_trans)
end
…
endtask
`uvm_object_utils(case0_sequence)
endclass
|
这样带来的问题是, 由于driver中接收的数据类型是uvm_sequence_item, 如果它要使用my_transaction或者your_transaction中的
成员变量, 必须使用cast转换:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
文件: src/ch6/section6.4/6.4.3/my_driver.sv
task my_driver::main_phase(uvm_phase phase);
my_transaction m_tr;
your_transaction y_tr;
…
while(1) begin
seq_item_port.get_next_item(req);
if($cast(m_tr, req)) begin
drive_my_transaction(m_tr);
`uvm_info("driver", "receive a transaction whose type is my_transaction", UVM_MEDIUM)
end
else if($cast(y_tr, req)) begin
drive_your_transaction(y_tr);
`uvm_info("driver", "receive a transaction whose type is your_transaction", UVM_MEDIUM)
end
else begin
`uvm_error("driver", "receive a transaction whose type is unknown")
end
seq_item_port.item_done();
end
endtask
|
p_sequencer的使用
考虑如下一种情况, 在sequencer中存在如下成员变量:
常规的使用 sequencer 中的成员变量的方法
1
2
3
4
5
6
7
8
9
10
11
12
|
文件: src/ch6/section6.4/6.4.4/my_sequencer.sv
class my_sequencer extends uvm_sequencer #(my_transaction);
bit[47:0] dmac;
bit [47:0] smac;
…
virtual function void build_phase(uvm_phase phase);
super.build_phase(phase);
void'(uvm_config_db#(bit[47:0])::get(this, "", "dmac", dmac));
void'(uvm_config_db#(bit[47:0])::get(this, "", "smac", smac));
endfunction
`uvm_component_utils(my_sequencer)
endclass
|
在其build_phase中, 使用config_db::get得到这两个成员变量的值。 之后sequence在发送transaction时,
必须将目的地址设置为dmac, 源地址设置为smac。 现在的问题是, 如何在sequence的body中得到这两个变量的值呢?
在6.4.1节中介绍嵌套的sequence时, 引入了m_sequencer这个属于每个sequence的成员变量,
但是如果直接使用m_sequencer得到这两个变量的值:
1
2
3
4
5
6
7
|
virtual task body();
…
repeat (10) begin
`uvm_do_with(m_trans, {m_trans.dmac == m_sequencer.dmac; m_trans.smac == m_sequencer.smac;})
end
…
endtask
|
如上写法会引起编译错误。 其根源在于m_sequencer是uvm_sequencer_base( uvm_sequencer的基类) 类型的, 而不是
my_sequencer类型的。 m_sequencer的原型为:
1
|
protected uvm_sequencer_base m_sequencer;
|
但是由于case0_sequence在my_sequencer上启动, 其中的m_sequencer本质上是my_sequencer类型的, 所以可以在my_sequence
中通过cast转换将m_sequencer转换成my_sequencer类型, 并引用其中的dmac和smac:
1
2
3
4
5
6
7
8
9
|
virtual task body();
my_sequencer x_sequencer;
…
$cast(x_sequencer, m_sequencer);
repeat (10) begin
`uvm_do_with(m_trans, {m_trans.dmac == x_sequencer.dmac; m_trans.smac == x_sequencer.smac;})
end
…
endtask
|
上述过程稍显麻烦。 在实际的验证平台中, 用到sequencer中成员变量的情况非常多。
UVM 推荐的 使用sequencer中成员变量的方法, 使用 uvm_declare_p_sequencer 声明
UVM考虑到这种情况, 内建了一个宏: uvm_declare_p_sequencer( SEQUENCER) 。
这个宏的本质是声明了一个SEQUENCER类型的成员变量, 如在定义sequence时, 使用此宏声明sequencer的类型:
1
2
3
4
5
6
7
|
文件: src/ch6/section6.4/6.4.4/my_case0.sv
class case0_sequence extends uvm_sequence #(my_transaction);
my_transaction m_trans;
`uvm_object_utils(case0_sequence)
`uvm_declare_p_sequencer(my_sequencer)
…
endclass
|
则相当于声明了如下的成员变量:
1
2
3
4
|
class case0_sequence extends uvm_sequence #(my_transaction);
my_sequencer p_sequencer;
…
endclass
|
UVM之后会自动将m_sequencer通过cast转换成p_sequencer。 这个过程在pre_body( ) 之前就完成了。 因此在sequence中可以
直接使用成员变量p_sequencer来引用dmac和smac:
1
2
3
4
5
6
7
8
9
10
11
|
文件: src/ch6/section6.4/6.4.4/my_case0.sv
class case0_sequence extends uvm_sequence #(my_transaction);
…
virtual task body();
…
repeat (10) begin
`uvm_do_with(m_trans, {m_trans.dmac == p_sequencer.dmac; m_trans.smac == p_sequencer.smac;})
end
…
endtask
endclass
|
sequence的派生与继承
sequence作为一个类, 是可以从其中派生其他sequence的:
1
2
3
4
5
6
7
8
9
10
11
12
|
文件: src/ch6/section6.4/6.4.5/my_case0.sv
class base_sequence extends uvm_sequence #(my_transaction);
`uvm_object_utils(base_sequence)
`uvm_declare_p_sequencer(my_sequencer)
function new(string name= "base_sequence");
super.new(name);
endfunction
//define some common function and task
endclass
class case0_sequence extends base_sequence;
…
endclass
|
由于在同一个项目中各sequence都是类似的, 所以可以将很多公用的函数或者任务写在base sequence中,
其他sequence都从此 sequence派生普通的sequence这样使用没有任何问题, 但对于那些使用了uvm_declare_p_sequence声明p_sequencer的base sequence,
在派生的sequence中是否也要调用此宏声明p_sequencer? 这个问题的答案是否定的, 因为uvm_declare_p_sequence的实质是在base sequence中声明了一个成员变量p_sequencer。 当其他的sequence从其派生时, p_sequencer依然是新的sequence的成员变量, 所以无须再声明一次了。
当然了, 如果再声明一次, 系统也并不会报错
1
2
3
4
5
6
7
8
9
10
|
class base_sequence extends uvm_sequence #(my_transaction);
`uvm_object_utils(base_sequence)
`uvm_declare_p_sequencer(my_sequencer)
…
endclass
class case0_sequence extends base_sequence;
`uvm_object_utils(case0_sequence)
`uvm_declare_p_sequencer(my_sequencer)
…
endclass
|
虽然这相当于连续声明了两个成员变量p_sequencer, 但是由于这两个成员变量一个是属于父类的, 一个是属于子类的, 所以
并不会出错。
virtual sequence的使用
sequence 使用 interface
参考另外一种是在sequence中实现
带双路输入输出端口的DUT
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
文件: src/ch6/section6.5/dut/dut.sv
module dut(clk,
rst_n,
rxd0,
rx_dv0,
rxd1,
rx_dv1,
txd0,
tx_en0,
txd1,
tx_en1);
input clk;
input rst_n;
input [7:0] rxd0;
input rx_dv0;
input [7:0] rxd1;
input rx_dv1;
output [7:0] txd0;
output tx_en0;
output [7:0] txd1;
output tx_en1;
reg [7:0] txd0;
reg tx_en0;
reg [7:0] txd1;
reg tx_en1;
always @(posedge clk) begin
if(!rst_n) begin
txd0 <= 8'b0;
tx_en0 <= 1'b0;
txd1 <= 8'b0;
tx_en1 <= 1'b0;
end
else begin
txd0 <= rxd0;
tx_en0 <= rx_dv0;
txd1 <= rxd1;
tx_en1 <= rx_dv1;
end
end
endmodule
|
上面这个DUT相当于在2.2.1节所示的DUT的基础上增加了一组数据口, 这组新的数据口与原先的数据口功能完全一样。
新的数据端口增加后, 由于这组新的数据端口与原先的一模一样, 所以可以在test中再额外实例化一个my_env:
1
2
3
4
5
6
7
8
9
10
11
12
|
文件: src/ch6/section6.5/6.5.1/base_test.sv
class base_test extends uvm_test;
my_env env0;
my_env env1
…
endclass
function void base_test::build_phase(uvm_phase phase);
super.build_phase(phase);
env0 = my_env::type_id::create("env0", this);
env1 = my_env::type_id::create("env1", this);
endfunction
|
在top_tb中做相应更改, 多增加一组my_if, 并通过config_db将其设置为新的env中的driver和monitor:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
文件: src/ch6/section6.5/6.5.1/top_tb.sv
module top_tb;
…
my_if input_if0(clk, rst_n);
my_if input_if1(clk, rst_n);
my_if output_if0(clk, rst_n);
my_if output_if1(clk, rst_n);
dut my_dut(.clk(clk),
.rst_n(rst_n),
.rxd0(input_if0.data),
.rx_dv0(input_if0.valid),
.rxd1(input_if1.data),
.rx_dv1(input_if1.valid),
.txd0(output_if0.data),
.tx_en0(output_if0.valid),
.txd1(output_if1.data),
.tx_en1(output_if1.valid));
…
initial begin
uvm_config_db#(virtual my_if)::set(null, "uvm_test_top.env0.i_agt.drv", "vif", input_if0);
uvm_config_db#(virtual my_if)::set(null, "uvm_test_top.env0.i_agt.mon","vif", input_if0);
uvm_config_db#(virtual my_if)::set(null, "uvm_test_top.env0.o_agt.mon", "vif", output_if0);
uvm_config_db#(virtual my_if)::set(null, "uvm_test_top.env1.i_agt.drv", "vif", input_if1);
uvm_config_db#(virtual my_if)::set(null, "uvm_test_top.env1.i_agt.mon", "vif", input_if1);
uvm_config_db#(virtual my_if)::set(null, "uvm_test_top.env1.o_agt.mon", "vif", output_if1);
end
endmodule
|
通过在测试用例中设置两个default sequence, 可以分别向两个数据端口施加激励:
1
2
3
4
5
6
|
文件: src/ch6/section6.5/6.5.1/my_case0.sv
function void my_case0::build_phase(uvm_phase phase);
super.build_phase(phase);
uvm_config_db#(uvm_object_wrapper)::set(this, "env0.i_agt.sqr.main_phase", "default_sequence", case0_sequence::type_id::get());
uvm_config_db#(uvm_object_wrapper)::set(this, "env1.i_agt.sqr.main_phase", "default_sequence", case0_sequence::type_id::get());
endfunction
|
sequence之间的简单同步
在这个新的验证平台中有两个driver, 它们原本是完全等价的, 但是出于某些原因的考虑, 如DUT要求driver0必须先发送一个
最大长度的包, 在此基础上driver1才可以发送包。 这是一个sequence之间同步的过程, 一种很自然的想法是, 将这个同步的过程
使用一个全局的事件来完成
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
文件: src/ch6/section6.5/6.5.2/my_case0.sv
event send_over;//global event
class drv0_seq extends uvm_sequence #(my_transaction);
…
virtual task body();
…
`uvm_do_with(m_trans, {m_trans.pload.size == 1500;})
->send_over;
repeat (10) begin
`uvm_do(m_trans)
`uvm_info("drv0_seq", "send one transaction", UVM_MEDIUM)
end
…
endtask
endclass
class drv1_seq extends uvm_sequence #(my_transaction);
…
virtual task body();
…
@send_over;
repeat (10) begin
`uvm_do(m_trans)
`uvm_info("drv1_seq", "send one transaction", UVM_MEDIUM)
end
…
endtask
endclass
|
之后, 通过uvm_config_db的方式分别将这两个sequence作为env0.i_agt.sqr和env1.i_agt.sqr的default_sequence:
1
2
3
4
5
6
|
文件: src/ch6/section6.5/6.5.2/my_case0.sv
function void my_case0::build_phase(uvm_phase phase);
super.build_phase(phase);
uvm_config_db#(uvm_object_wrapper)::set(this, "env0.i_agt.sqr.main_phase", "default_sequence", drv0_seq::type_id::get());
uvm_config_db#(uvm_object_wrapper)::set(this, "env1.i_agt.sqr.main_phase", "default_sequence", drv1_seq::type_id::get());
endfunction
|
当进入到main_phase时, 这两个sequence会同步启动, 但是由于drv1_seq要等待send_over事件的到来, 所以它并不会马上产生 transaction,
而drv0_seq则会直接产生transaction。 当drv0_seq发送完一个最长包后, send_over事件被触发, 于drv1_seq开始产生 transaction
sequence之间的复杂同步 (virtual sequence)
实现sequence之间同步的最好的方式就是使用virtual sequence。 从字面上理解, 即虚拟的sequence。 虚拟的意思就是它根本就
不发送transaction, 它只是控制其他的sequence, 起统一调度的作用。
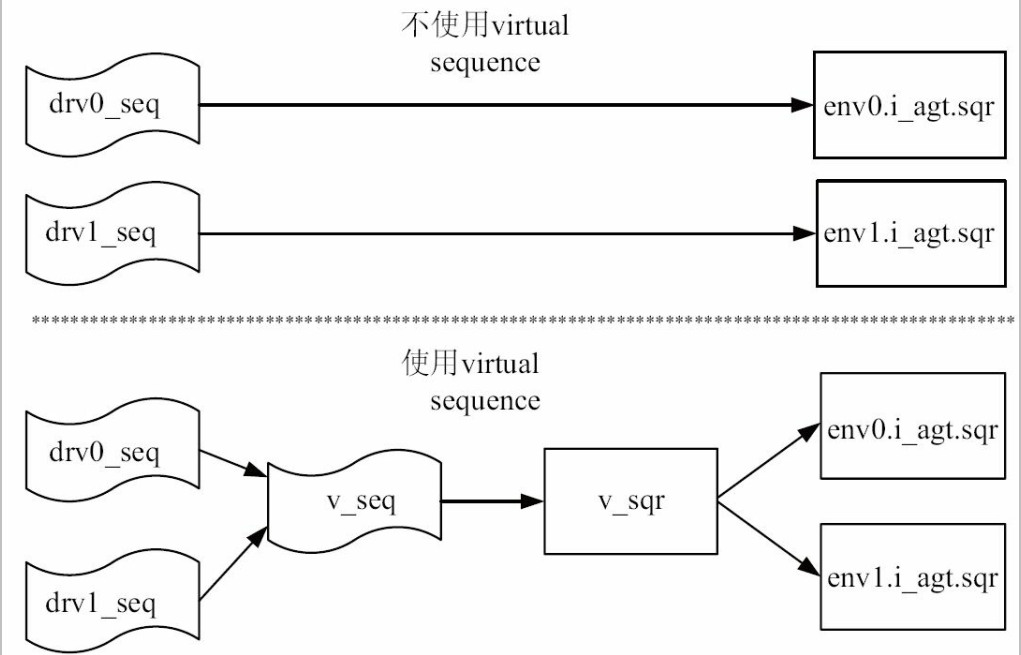
如上图所示:
为了使用virtual sequence, 一般需要一个virtual sequencer。 virtual sequencer里面包含指向其他真实sequencer的指针:
在my_vsqr.sv 中声明sequencer 指针
1
2
3
4
5
6
|
文件: src/ch6/section6.5/6.5.3/uvm_do_on/my_vsqr.sv
class my_vsqr extends uvm_sequencer;
my_sequencer p_sqr0;
my_sequencer p_sqr1;
…
endclass
|
在base_test中, 实例化vsqr, 并将相应的sequencer赋值给vsqr中的sequencer的指针:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
文件: src/ch6/section6.5/6.5.3/uvm_do_on/base_test.sv
class base_test extends uvm_test;
my_env env0;
my_env env1;
my_vsqr v_sqr;
…
endclass
function void base_test::build_phase(uvm_phase phase);
super.build_phase(phase);
env0 = my_env::type_id::create("env0", this);
env1 = my_env::type_id::create("env1", this);
v_sqr = my_vsqr::type_id::create("v_sqr", this);
endfunction
function void base_test::connect_phase(uvm_phase phase);
v_sqr.p_sqr0 = env0.i_agt.sqr;
v_sqr.p_sqr1 = env1.i_agt.sqr;
endfunction
|
在case 中的 virtual sequence 中则可以使用uvm_do_on系列宏来发送transaction:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
文件: src/ch6/section6.5/6.5.3/uvm_do_on/my_case0.sv
class drv0_seq extends uvm_sequence #(my_transaction);
…
virtual task body();
repeat (10) begin
`uvm_do(m_trans)
`uvm_info("drv0_seq", "send one transaction", UVM_MEDIUM)
end
endtask
endclass
class drv1_seq extends uvm_sequence #(my_transaction);
…
virtual task body();
repeat (10) begin
`uvm_do(m_trans)
`uvm_info("drv1_seq", "send one transaction", UVM_MEDIUM)
end
endtask
endclass
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
文件: src/ch6/section6.5/6.5.3/uvm_do_on/my_case0.sv
class case0_vseq extends uvm_sequence;
`uvm_object_utils(case0_vseq)
`uvm_declare_p_sequencer(my_vsqr)
…
virtual task body();
my_transaction tr;
drv0_seq seq0;
drv1_seq seq1;
…
`uvm_do_on_with(tr, p_sequencer.p_sqr0, {tr.pload.size == 1500;})
`uvm_info("vseq", "send one longest packet on p_sequencer.p_sqr0", UVM_MEDIUM)
fork
`uvm_do_on(seq0, p_sequencer.p_sqr0);
`uvm_do_on(seq1, p_sequencer.p_sqr1);
join
…
endtask
endclass
|
在case0_vseq中, 先使用uvm_do_on_with在p_sequencer.sqr0上发送一个最长包, 当其发送完毕后, 再启动drv0_seq和
drv1_seq。 这里的drv0_seq和drv1_seq非常简单, 两者之间不需要为同步做任何事情.
在使用uvm_do_on宏的情况下, 虽然seq0是在case0_vseq中启动, 但是它最终会被交给p_sequencer.p_sqr0, 也即env0.i_agt.sqr
而不是v_sqr。 这个就是virtual sequence和virtual sequencer中virtual的来源。 它们各自并不产生transaction, 而只是控制其他的
sequence为相应的sequencer产生transaction。 virtual sequence和virtual sequencer只是起一个调度的作用。 由于根本不直接产生
transaction, 所以virtual sequence和virtual sequencer在定义时根本无需指明要发送的transaction数据类型
如果不使用uvm_do_on宏, 那么也可以手工启动sequence, 其效果完全一样。 手工启动sequence的一个优势是可以向其中传递一些值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
文件: src/ch6/section6.5/6.5.3/start/my_case0.sv
class read_file_seq extends uvm_sequence #(my_transaction);
my_transaction m_trans;
string file_name;
…
endclass
…
class case0_vseq extends uvm_sequence;
…
virtual task body();
my_transaction tr;
read_file_seq seq0;
drv1_seq seq1;
…
`uvm_do_on_with(tr, p_sequencer.p_sqr0, {tr.pload.size == 1500;})
`uvm_info("vseq", "send one longest packet on p_sequencer.p_sqr0", UVM_MEDIUM)
seq0 = new("seq0");
seq0.file_name = "data.txt";
seq1 = new("seq1");
fork
seq0.start(p_sequencer.p_sqr0);
seq1.start(p_sequencer.p_sqr1);
join
…
endtask
endclass
|
设置virtual seqence 作为 default sequence
1
2
3
4
5
|
文件: src/ch6/section6.5/6.5.3/uvm_do_on/my_case0.sv
function void my_case0::build_phase(uvm_phase phase);
…
uvm_config_db#(uvm_object_wrapper)::set(this, "v_sqr.main_phase", "default_sequence", case0_vseq::type_id::get());
endfunction
|
在 virtual seqence 中启动其他的virtual sequence
1
2
3
4
5
6
7
8
9
10
|
文件: src/ch6/section6.5/6.5.3/multi_vseq/my_case0.sv
class case0_vseq extends uvm_sequence;
…
virtual task body();
cfg_vseq cvseq;
…
`uvm_do(cvseq)
…
endtask
endclass
|
其中cfg_vseq是另外一个已经定义好的virtual sequence。