UVM 高级应用
interface
interface实现driver的部分功能
简单的interface 如下:
1
2
3
4
|
interface my_if(input clk, input rst_n);
logic [7:0] data;
logic valid;
endinterface
|
但是实际上interface能做的事情远不止如此。 在interface中可以定义任务与函数。 除此之外, 还可以在interface中使用always语句和initial语句
在现代高速数据接口中, 如USB3.0、 1394b、 Serial ATA、 PCI Express、 HDMI、 DisplayPort, 数据都是以串行的方式传输的。
以传输一个8bit的数据为例, 出于多种原因的考虑, 这些串行传输的数据并不是简单地将这8bit从bit0到bit7轮流发送出去, 而是要
经过一定的编码, 如8b10b编码, 这种编码技术将8bit的数据以10bit来表示, 从而可以增加数据传输的可靠性。
从8bit到10bit的转换有专门的算法完成。 通常来说, 可以在driver中完成这种转换, 并将串行的数据驱动到接口上:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
task my_driver::drive_one_pkt(my_transaction tr);
byte unsigned data_q[];
bit [9:0] data10b_q[];
int data_size;
data_size = tr.pack_bytes(data_q) / 8;
data10b_q = new[data_size];
for(int i = 0; i < data_size; i++)
data10b_q[i] = encode_8b10b(data_q[i]);
for ( int i = 0; i < data_size; i++ ) begin
@(posedge vif.p_clk);
for(int j = 0; j < 10; j++) begin
@(posedge vif.s_clk);
vif.sdata <= data10b_q[i][j];
end
end
endtask
|
上述代码中p_clk为并行的时钟, 而s_clk为串行的时钟, 后者是前者的10倍频率。
这些事情完全可以在interface中完成。 由于8b10b转换的动作适用于任意要驱动的数据,
换言之, 这是一个“always”的动作, 因此可以在interface中使用always语句:
在interactive 中使用 always 语句
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
interface my_if(input p_clk, input s_clk, input rst_n);
logic sdata;
logic [7:0] data_8b;
logic [9:0] data_10b;
always@(posedge p_clk) begin
data_10b <= encode_8b10b(data_8b);
end
always@(posedge p_clk) begin
for(int i = 0; i < 10; i++) begin
@(posedge s_clk);
sdata <= data_10b[i];
end
end
endinterface
|
相应的, 数据在driver中可以只驱动到interface的并行接口上即可:
1
2
3
4
5
6
7
8
9
|
task my_driver::drive_one_pkt(my_transaction tr);
byte unsigned data_q[];
int data_size;
data_size = tr.pack_bytes(data_q) / 8;
for ( int i = 0; i < data_size; i++ ) begin
@(posedge vif.p_clk);
vif.data_8b <= data_q[i];
end
endtask
|
在interface中使用类似assign等语句:
1
2
3
4
|
interface my_if(input p_clk, input s_clk, input rst_n);
assign data_10b = (err_8b10b ? data_10b_wrong : data_10b_right);
…
endinterface
|
在interface中还可以实例化其他interface
由于8b10b转换是一个比较独立的功能, 可以将它们放在一个interface中:
1
2
3
4
5
6
7
8
|
interface if_8b10b();
function bit[9:0] encode(bit[7:0] data_8b);
…
endfunction
function bit[7:0] decode(bit[9:0] data_10b);
…
endfunction
endinterface
|
然后在interface中实例化这个新的interface, 并调用其中的函数:
1
2
3
4
5
6
7
8
|
interface my_if(input p_clk, input s_clk, input rst_n);
…
if_8b10b encode_if();
always@(posedge p_clk) begin
data_10b <= encode_if.encode(data_8b);
end
…
endinterface
|
这个新加入的interface与DUT根本没有任何接触, 它只是为了提高代码的可重用性, 单纯起到了一个封装的作用。 在项目中
可以实例化这个interface用于编码, 在其他项目中, 如一个需要10b到8b解码的项目中, 可以实例化它用于解码。
interface可以代替driver做很多事情, 但是并不能代替driver做所有的事情。 interface只适用于做一些低层次的转换, 如上述的
8b10b转换、 曼彻斯特编码等。 这些转换动作是与transaction完全无关的。
使用interface代替driver 有两个好处:
- 第一个好处是可以让driver从底层繁杂的数据处理中解脱出来, 更加专注于处理高层数据。
-
第二个好处是有更多的数据出现在interface中, 这会对调试起到很大的帮助。 在interactive 中使用 always 语句 中
interface内sdata、 data10b、 data8b的信号是在波形文件中有记录的, 因此可以使用查看波形的软件查看其中的信号。
如果8b10b编码的工作是在driver中完成的, 换言之, interface中只有data10b或者sdata,
那么最后的波形文件中一般不会有data8b的信息( 除非根据仿真工具做某些特殊的、 复杂的设置, 否则driver中的变量很难记录在波形文件中),
这会增加调试的难度。 这种调试既包括对RTL的调试, 也包括driver的调试。
不过, 当使用interface完成这些转换后, 如果想构造这些转换异常的测试用例, 则稍显麻烦。 如构造一个8b10b转换的错误,
需要在interface中加入一个标志位err_8b10b, 根据此标志位的数据决定向数据线上发送何种数据。
而如果这种转换是在driver完成的, 有两种选择, 一是在正常的driver中加入异常driver的处理代码; 二是重新编写一个全新的
异常driver, 将原来的driver使用factory机制重载掉。
无论是哪种方式都能实现其目的。 相比来说, 在interface上实现转换能够更有助于调试, 这一优势完全可以弥补其劣势。
可变时钟
有时在验证平台中需要频率变化的时钟。 可变时钟有三种,
第一种是在不同测试用例之间时钟频率不同, 但是在同一测试用例中保持不变。 在一些应用中, 如HDMI协议中, 其图像的时钟信号就根据发送( 接收) 图像的分辨率的变化而变化。 当不同的测试用例测试不同分辨率的图像时, 就需要在不同测试用例中设置不同的时钟频率。第二种是在同一个测试用例中存在时钟频率变换的情况。 芯片上的时钟是由PLL产生的。 但是PLL并不是一开始就会产生稳定的时钟, 而是会有一段过渡期,在这段过渡期内, 其时钟频率是一直变化的。 有时候不关心这段过渡期时, 而只关心过渡期前和过渡期后的时钟频率。第三种可变时钟和第二种很像, 但是它既关心过渡期前后的时钟, 也关心PLL在过渡期的行为。 为了模仿这段过渡期内频率对芯片的影响, 就需要一个可变时钟模型。 除此之外, 在正常工作时, 理论上PLL会输出稳定的时钟, 但是在实际使用中, PLL 的时钟频率总是在某个范围内以某种方式( 如正弦) 变化,如设置为27M的时钟可能在26.9M~27.1M变换。 为了模仿这种变化,也需要一个可变时钟模型。
生成第一种时钟
在通常的验证平台中, 时钟都是在top_tb中实现的:
1
2
3
4
5
6
|
initial begin
clk = 0;
forever begin
#100 clk = ~clk;
end
end
|
这种时钟都是固定的。 在传统的实现方式中, 如果要实现第一种可变时钟, 可以将上述模块独立成一个文件:
1
2
3
4
5
6
7
8
9
|
`ifndef TEST_CLK
`define TEST_CLK
initial begin
clk = 0;
forever begin
#100 clk = ~clk;
end
end
`endif
|
然后将上述文件通过inlude的方式包含在top_tb中:
1
2
3
4
5
|
module top_tb();
…
`include "test_clk.sv"
…
endmodule
|
当需要可变时钟时, 只需要重新编写一个test_clk.v文件即可。 这种方式是Verilog搭建的验证平台中经常用到的做法。
除了上述这种Verilog式的方式外, 要实现第一种可变的时钟, 可以使用config_db, 在测试用例中设置时钟周期:
1
2
3
4
5
|
文件: src/ch10/section10.1/10.1.2/simple/my_case0.sv
function void my_case0::build_phase(uvm_phase phase);
…
uvm_config_db#(real)::set(this, "", "clk_half_period", 200.0);
endfunction
|
在top_tb中使用config_db: : get得到设置的周期:
1
2
3
4
5
6
7
8
9
10
11
|
文件: src/ch10/section10.1/10.1.2/simple/top_tb.sv
initial begin
static real clk_half_period = 100.0;
clk = 0;
#1;
if(uvm_config_db#(real)::get(uvm_root::get(), "uvm_test_top", "clk_half_period", clk_half_period))
`uvm_info("top_tb", $sformatf("clk_half_period is %0f", clk_half_per iod), UVM_MEDIUM)
forever begin
#(clk_half_period*1.0ns) clk = ~clk;
end
end
|
在这种设置的方式中, 使用了非直线的获取。 my_case0中的config_db::set看起来比较奇怪: 这是一个设置给自己的参数。
但是真正使用这个参数是在top_tb中, 而不是在my_case0中。 由于config_db::set是在0时刻执行,
而如果 config_db::get也在0时刻执行, 那么可能无法得到设置的数值, 所以在top_tb中, 在config_db::get前有1个时间单位的延迟 。
这种生成可变时钟的方式只适用于第一种可变时钟。
生成第二钟时钟
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
文件: src/ch10/section10.1/10.1.2/complex/top_tb.sv
initial begin
static real clk_half_period = 100.0;
clk = 0;
fork
forever begin
uvm_config_db#(real)::wait_modified(uvm_root::get(), "uvm_test_top", "clk_half_period"); // 等待 clk_half_period 被修改完成
void'(uvm_config_db#(real)::get(uvm_root::get(), "uvm_test_top", "clk_half_period", clk_half_period));
`uvm_info("top_tb", $sformatf("clk_half_period is %0f", clk_half_period), UVM_MEDIUM)
end
forever begin
#(clk_half_period*1.0ns) clk = ~clk;
end
join
end
|
在测试用例中可以随着时间的变换而设置不同的时钟:
1
2
3
4
5
6
7
|
文件: src/ch10/section10.1/10.1.2/complex/my_case0.sv
task my_case0::main_phase(uvm_phase phase);
#100000;
uvm_config_db#(real)::set(this, "", "clk_half_period", 200.0);
#100000;
uvm_config_db#(real)::set(this, "", "clk_half_period", 150.0);
endtask
|
但是, 使用这种config_db的方式很难实现第三种可变时钟。
实现第三种时钟
可以专门编写一个时钟接口:
1
2
3
4
|
文件: src/ch10/section10.1/10.1.2/component/clk_if.sv
interface clk_if();
logic clk;
endinterface
|
在top_tb中实例化这个接口, 并在需要时钟的地方以如下的方式引用:
1
2
3
4
5
6
|
文件: src/ch10/section10.1/10.1.2/component/top_tb.sv
clk_if cif();
…
dut my_dut(.clk(cif.clk),
.rst_n(rst_n),
…
|
为可变时钟从uvm_component派生一个类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
文件: src/ch10/section10.1/10.1.2/component/clk_model.sv
class clk_model extends uvm_component;
`uvm_component_utils(clk_model)
virtual clk_if vif;
real half_period = 100.0;
…
function void build_phase(uvm_phase phase);
super.build_phase(phase);
if(!uvm_config_db#(virtual clk_if)::get(this, "", "vif", vif))
`uvm_fatal("clk_model", "must set interface for vif")
void'(uvm_config_db#(real)::get(this, "", "half_period", half_period));
`uvm_info("clk_model", $sformatf("clk_half_period is %0f", half_period), UVM_MEDIUM)
endfunction
virtual task run_phase(uvm_phase phase);
vif.clk = 0;
forever begin
#(half_period*1.0ns) vif.clk = ~vif.clk;
end
endtask
endclass
|
在env中, 实例化此类:
1
2
3
4
5
6
7
8
9
10
11
12
|
文件: src/ch10/section10.1/10.1.2/component/my_env.sv
class my_env extends uvm_env;
…
clk_model clk_sys;
…
virtual function void build_phase(uvm_phase phase);
…
clk_sys = clk_model::type_id::create("clk_sys", this);
…
endfunction
…
endclass
|
在这种使用方式中, 时钟接口被封装在了一个component中。 在需要新的时钟模型时, 只需要从clk_model派生一个新的类,
然后在新的类中实现时钟模型。 使用factory机制的重载功能将clk_model用新的类重载掉。 通过这种方式, 可以将时钟设置为任意
想要的行为。
layer sequence
layer sequence 可以将复杂的 sequence分离成各种独立的sequence
layer sequence的示例
产生ip_transaction的sequence如下:
1
2
3
4
5
6
7
8
9
10
11
12
|
文件: src/ch10/section10.2/10.2.2/my_case0.sv
class ip_sequence extends uvm_sequence #(ip_transaction);
…
virtual task body();
ip_transaction ip_tr;
repeat (10) begin
`uvm_do_with(ip_tr, {ip_tr.src_ip == 'h9999; ip_tr.dest_ip == 'h10000;})
end
#100;
endtask
`uvm_object_utils(ip_sequence)
endclass
|
其相应的sequencer如下:
1
2
3
4
5
6
7
|
文件: src/ch10/section10.2/10.2.2/ip_sequencer.sv
class ip_sequencer extends uvm_sequencer #(ip_transaction);
function new(string name, uvm_component parent);
super.new(name, parent);
endfunction
`uvm_component_utils(ip_sequencer)
endclass
|
这个sequencer需要在my_agent中实例化, 在这种情况下, my_agent中有两个sequencer:
1
2
3
4
5
6
7
8
9
10
|
文件: src/ch10/section10.2/10.2.2/my_agent.sv
function void my_agent::build_phase(uvm_phase phase);
super.build_phase(phase);
if (is_active == UVM_ACTIVE) begin
ip_sqr = ip_sequencer::type_id::create("ip_sqr", this);
sqr = my_sequencer::type_id::create("sqr", this);
drv = my_driver::type_id::create("drv", this);
end
mon = my_monitor::type_id::create("mon", this);
endfunction
|
要使用layer sequence, 最关键的问题是如何将ip_transaction能够交给产生my_transaction的sequence。 由于ip_transaction是由一
个sequence产生的, 模仿driver从sequencer获取transaction的方式, 在my_sequencer中加入一个端口, 并将其实例化:
1
2
3
4
5
6
7
8
9
10
|
文件: src/ch10/section10.2/10.2.2/my_sequencer.sv
class my_sequencer extends uvm_sequencer #(my_transaction);
uvm_seq_item_pull_port #(ip_transaction) ip_tr_port;
…
function void build_phase(uvm_phase phase);
super.build_phase(phase);
ip_tr_port = new("ip_tr_port", this);
endfunction
…
endclass
|
在my_agent中, 将这个端口和ip_sqr的相关端口连接在一起:
1
2
3
4
5
6
7
8
9
|
文件: src/ch10/section10.2/10.2.2/my_agent.sv
function void my_agent::connect_phase(uvm_phase phase);
super.connect_phase(phase);
if (is_active == UVM_ACTIVE) begin
drv.seq_item_port.connect(sqr.seq_item_export);
sqr.ip_tr_port.connect(ip_sqr.seq_item_export);
end
ap = mon.ap;
endfunction
|
之后在产生my_transaction的sequence中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
文件: src/ch10/section10.2/10.2.2/my_case0.sv
class my_sequence extends uvm_sequence #(my_transaction);
…
virtual task body();
my_transaction m_tr;
ip_transaction ip_tr;
byte unsigned data_q[];
int data_size;
while(1) begin
p_sequencer.ip_tr_port.get_next_item(ip_tr);
data_size = ip_tr.pack_bytes(data_q) / 8;
m_tr = new("m_tr");
assert(m_tr.randomize with{m_tr.pload.size() == data_size;});
for(int i = 0; i < data_size; i++) begin
m_tr.pload[i] = data_q[i];
end
`uvm_send(m_tr)
p_sequencer.ip_tr_port.item_done();
end
endtask
`uvm_object_utils(my_sequence)
`uvm_declare_p_sequencer(my_sequencer)
endclass
|
由于需要用到sequencer中的ip_tr_port, 所以要使用declare_p_sequencer宏声明sequencer。 这个sequence被做成了一个无限循环
的sequence, 因为它需要时刻从ip_tr_port得到新的ip_transaction, 这类似于driver中的无限循环。 由于设置了无限循环, 所以不能
在其中提起或者撤销objection。 objection要在ip_sequence中控制。
之后, 需要启动这两个sequence。 可以使用default_sequence的形式:
1
2
3
4
5
6
|
文件: src/ch10/section10.2/10.2.2/my_case0.sv
function void my_case0::build_phase(uvm_phase phase);
super.build_phase(phase);
uvm_config_db#(uvm_object_wrapper)::set(this, "env.i_agt.ip_sqr.main_phase", "default_sequence", ip_sequence::type_id::get());
uvm_config_db#(uvm_object_wrapper)::set(this, "env.i_agt.sqr.main_phase", "default_sequence", my_sequence::type_id::get());
endfunction
|
也可以使用default_sequence的形式, 前提是vsqr中已经有成员变量指向相应的sequencer:
1
2
3
4
5
6
7
8
9
10
|
class case0_vseq extends uvm_sequence;
virtual task body();
ip_sequence ip_seq;
my_sequence my_seq;
fork
`uvm_do_on(my_seq, p_sequencer.p_my_sqr)
join_none
`uvm_do_on(ip_seq, p_sequencer.p_ip_sqr)
endtask
endclass
|
当后面构建CRC错误包的激励时, 只需要建立crc_sequence, 并在my_sequecer上启动。 而此时ip_sequencer上依然是
ip_sequence, 不受影响
当需要构建checksum错误的激励时, 也只需要建立cks_err_seq, 并在ip_sequencer上启动, 此时my_sequencer上启动的是
my_sequence, 不受影响
layer sequence对于初学者来说会比较复杂。 在上一节中, layer sequence只是解决问题的一种策略, 另外一种策略是在
base_sequence中写函数/任务。 在这个例子中, 相比base_sequence, layer sequence并没有明显的优势。 但是当问题非常复杂时,
layer sequence会逐渐体现出其优势。 在大型的验证平台中, layer sequence的应用非常多。
layer sequence与try_next_item
在layer sequence的示例 中最终的my_driver使用get_next_item从my_sequencer中得到数据:
1
2
3
4
5
6
7
8
9
|
文件: src/ch10/section10.2/10.2.2/my_driver.sv
task my_driver::main_phase(uvm_phase phase);
…
while(1) begin
seq_item_port.get_next_item(req);
drive_one_pkt(req);
seq_item_port.item_done();
end
endtask
|
与get_next_item相比, try_next_item更加接近实际情况。 在实际应用中, try_next_item用得更多。
现在将get_next_item改为try_next_item:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
task my_driver::drive_idle();
`uvm_info("my_driver", "item is null", UVM_MEDIUM)
@(posedge vif.clk);
endtask
task my_driver::main_phase(uvm_phase phase);
…
while(1) begin
seq_item_port.try_next_item(req);
if(req == null) begin
drive_idle();
end
else begin
`uvm_info("my_driver", "get one pkt", UVM_MEDIUM)
drive_one_pkt(req);
seq_item_port.item_done();
end
end
endtask
|
重新运行上节的例子, 会发现在前后两个有效的req之间, my_driver总会打印一句“item is null”, 说明driver没有得到 transaction:
1
2
3
|
UVM_INFO my_driver.sv(39) @ 81100000: uvm_test_top.env.i_agt.drv [my_driver] get one pkt
UVM_INFO my_driver.sv(24) @ 166300000: uvm_test_top.env.i_agt.drv [my_driver] item is null
UVM_INFO my_driver.sv(39) @ 166500000: uvm_test_top.env.i_agt.drv [my_driver] get one pkt
|
当my_driver没有得到transaction时, 它只是等待一个时钟, 相当于空闲一个时钟。 在某些协议中, 除非故意出现空闲, 否则这
样正常的驱动数据中出现的空闲将会导致时序错误。 避免这个问题的一个办法是不用try_next_item, 而使用get_next_item。 但是正
如一开始说的, try_next_item更接近真实的情况。 使用get_next_item有两个问题:
- 一是某些协议并不是上电复位后马上开始发送正常数据, 而是开始发送一些空闲数据sequence, 这些数据有特定的要求, 并不是一成不变的。 当空闲数据sequence发送完毕 后, 经过某些交互开始发送正常的数据。 一旦开始发送正常数据, 就不能再在正常数据中间插入空闲数据。 对于这种情况, 如果 使用get_next_item, 那么将难以处理在上电复位后要求发送的空闲数据sequence。
- 二是当drop_objection后的drain_time 的这段时间也要求发送空闲数据sequence。 但是此时sequence已经不提供transaction了, 所以my_driver无法按照要求驱动这些空闲数据sequence。
所以还是应该使用try_next_item
SystemVerilog是按照事件驱动进行仿真的。 在每一个时刻有很多事件。 为了处理这众多的事件, SystemVerilog使用时间槽来管理它们。 如下图所示, 时间轴上方为n时刻的部分时间槽, 时间轴下方为n+1时刻的部分时间槽。 在n时刻的时间槽p中, driver驱动数据并调用item_done, 以及调用try_next_item试图获取下一个transaction。 my_sequencer一方面使try_next_item等待一个时间槽, 另外一方面将item_done转发给my_sequence( 事实上, 并不是简单的转发, 而是通知my_sequence当前的transaction已经被driver驱动完毕, 可以产生下一个transaction, 为了方便, 可以认为转发item_done) 。 这里为什么要令try_next_item等待一个时间槽呢? 因 为my_sequence收到item_done的信息, 向其sequencer递交产生下一个transaction的请求, 及最后生成transaction交给sequencer是需要时间来完成的。 my_sequence收到item_done后, 也向ip_sequencer发出item_done信息, 并使用get_next_item获取下一个item。 ip_sequencer把item_done转发给ip_sequence。 ip_sequence收到item_done后, 结束上一个uvm_do, 开始下一个uvm_do, 产生新的item。 上述这一切都是在时间槽p中完成的。
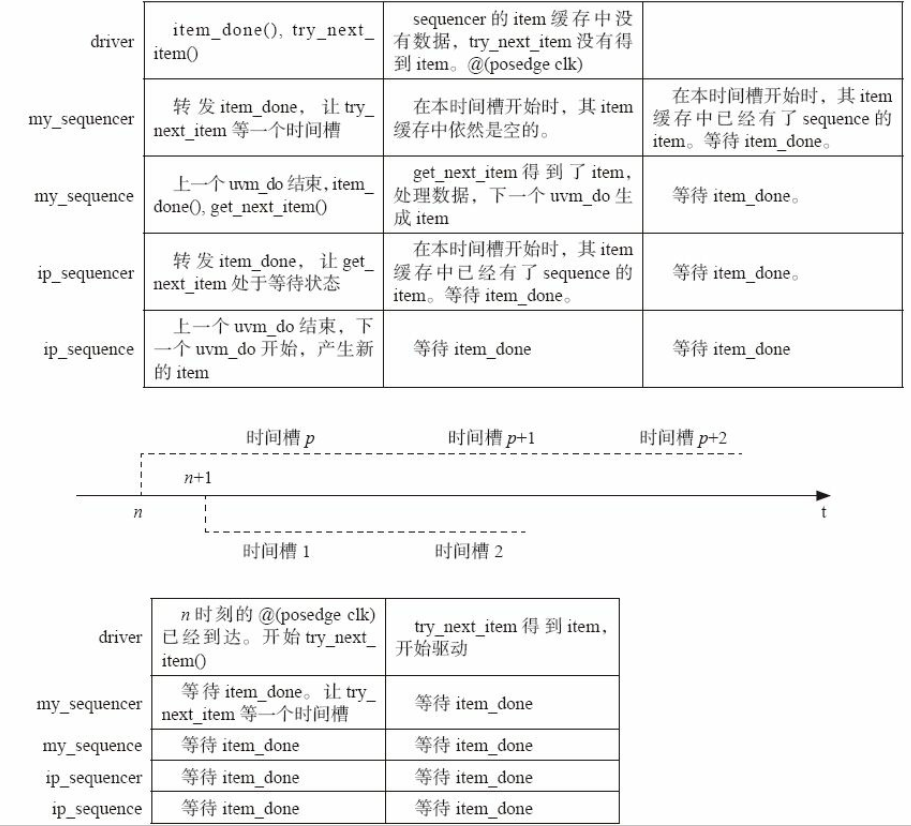
在时间槽p结束时( 或者说时间槽p+1开始时) , ip_sequencer的item缓存中已经有数据了, 此时my_sequence的get_next_item得到了数据。 但是此时, my_sequencer的item缓存中依然是空的。 driver发出的try_next_item在这个时间槽发现my_sequencer的item缓存为空, 于是直接返回null, driver得到null后, 开始drive_idle, 即等待下一个时钟的上升沿
在时间槽p+1结束时( 或者说时间槽p+2开始时) , my_sequence已经将生成的数据送入my_sequencer的item缓存了。 但是此时driver并没有向my_sequencer索要数据, 而是处于@( posedge clk) 的状态。
在n+1时刻, 下一个时钟的上升沿到来。 在n+1时刻的时间槽1, driver开始try_next_item。 此时my_sequencer收到了这个请求,虽然此时它的缓存中是非空的, 但是依然让try_next_item等待一个时间槽。 在n+1时刻的时间槽2, driver的try_next_item如愿得到了想要的transaction。
从上述过程可以看出, 主要问题在于n时刻时driver的try_next_item调用过早。 如果不是在时间槽p调用, 而是在时间槽p+1调用, 那么在时间槽p+2时, try_next_item就可以由my_sequencer的item缓存中得到transaction了。 在UVM中, 这可以通过调用任务 uvm_wait_for_nba_region来实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
文件: src/ch10/section10.2/10.2.3/my_driver.sv
task my_driver::drive_idle();
`uvm_info("my_driver", "item is null", UVM_MEDIUM)
@(posedge vif.clk);
endtask
task my_driver::main_phase(uvm_phase phase);
…
while(1) begin
uvm_wait_for_nba_region();
seq_item_port.try_next_item(req);
if(req == null) begin
dirve_idle();
end
else begin
drive_one_pkt(req);
seq_item_port.item_done();
end
end
endtask
|
错峰技术的使用
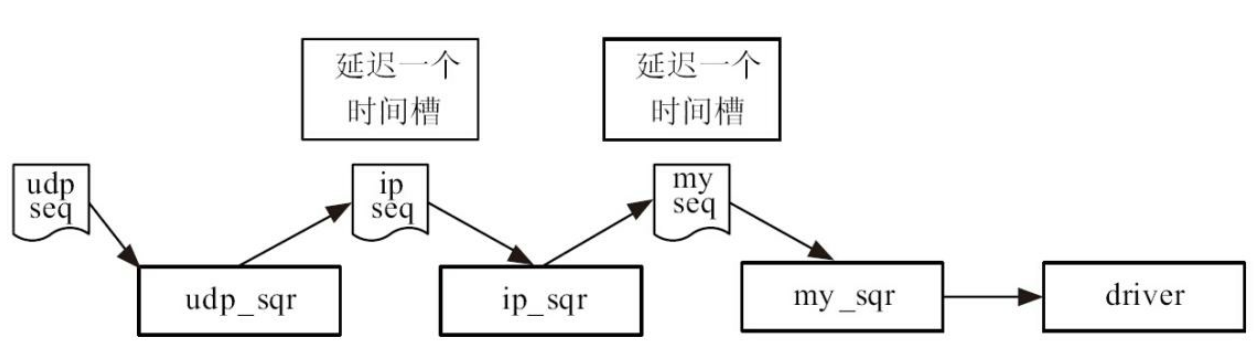
如上图所示, 从udp_seq发出item到driver的try_next_item能够检测到需要2个时间槽的延时。 只增加一个uvm_wait_for_nba_region是没有用处的, 需要再增加一个。 当layer sequence的层数再增加时, 相应的也需要再增加。 这种解决方案显得非常的丑陋。
上述问题的关键在于item_done和try_next_item是在同一时刻被调用, 这导致了时间槽的竞争。 如果能够将它们错开调用, 那
么这个问题也将不会是问题:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
文件: src/ch10/section10.2/10.2.4/my_driver.sv
task my_driver::drive_idle();
`uvm_info("my_driver", "item is null", UVM_MEDIUM)
endtask
task my_driver::main_phase(uvm_phase phase);
…
while(1) begin
@(posedge vif.clk);
seq_item_port.try_next_item(req);
if(req == null) begin
drive_idle();
end
else begin
drive_one_pkt(req);
seq_item_port.item_done();
end
end
endtask
|
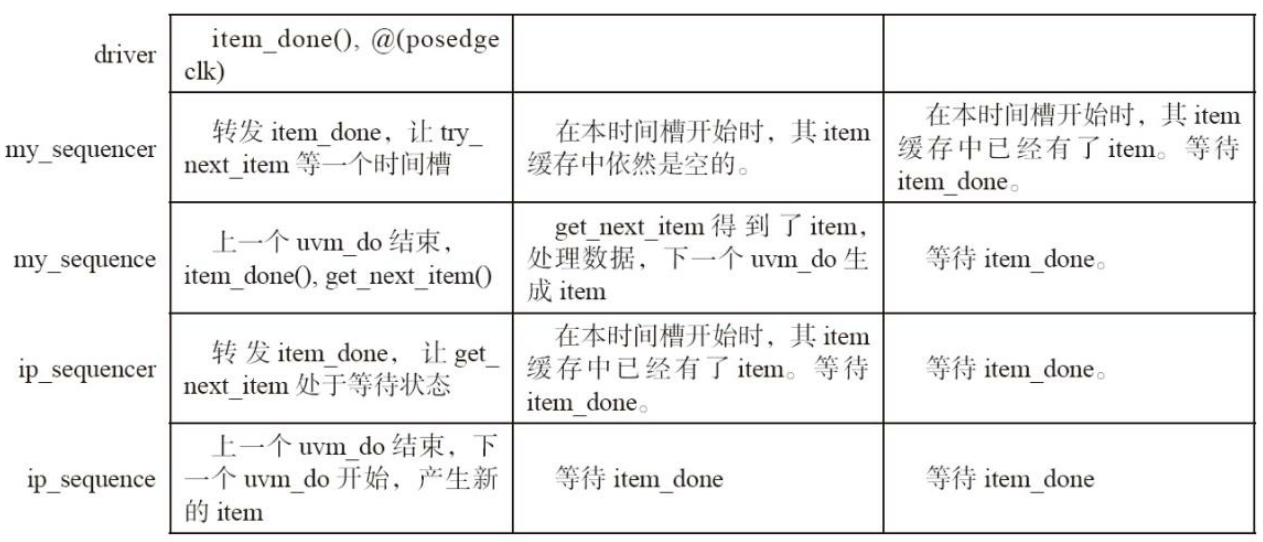
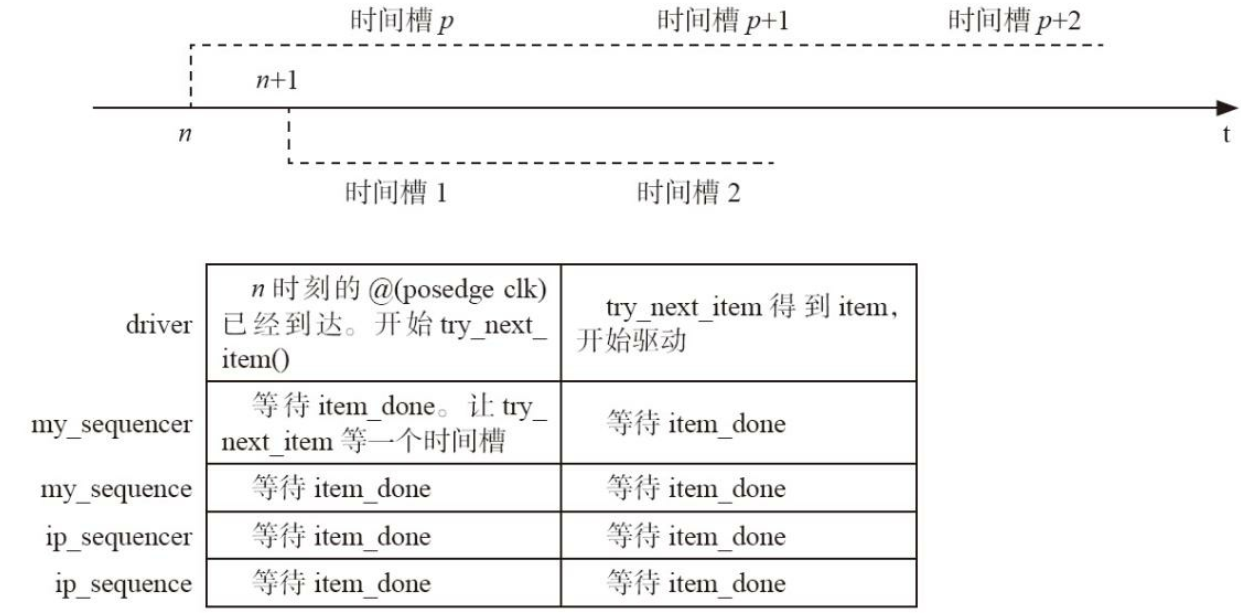
在item_done被调用后, 并不是立即调用try_next_item, 而是等待下一个时钟的上升沿到来后再调用。 在这种情况下,带时间槽的调用关系图如下:
sequence的其他问题
心跳功能的实现
在某些协议中, 需要driver每隔一段时间向DUT发送一些类似心跳的信号。 这些心跳信号的包与其他的普通的包并没有本质上
的区别, 其使用的transaction也都是普通的transaction。
发送这种心跳包有两种选择,
一种是在driver中实现, driver负责包的产生、 发送:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
task my_driver::main_phase(uvm_phase phase);
fork
while(1) begin
#delay;
drive_heartbeat_pkt();
end
while(1) begin
seq_item_port.get_next_item(req);
drive_one_pkt(req);
seq_item_port.item_done();
end
join
endtask
|
另外一种是在sequence中实现
这个sequence被做成一种无限循环的sequence, 这个sequence精确地计时, 当需要发送心跳包时, 生成一个心跳包并发送出去:
1
2
3
4
5
6
7
8
|
class heartbeat_sequence extends uvm_sequence #(my_transaction);
virtual task body();
while(1) begin
#delay;
`uvm_do(heartbeat_tr)
end
endtask
endclass
|
使用sequence的实现方式需要在sequence中引入时序, 这可能会让只在sequence中写uvm_do宏的用户感觉相当不习惯。 虽然在上述示例代码中使用了绝对延时, 但是一般在代码中最好不要使用绝对延时, 而使用virtual sequence。 一般在sequencer中通过 config_db::get得到virtual sequence, 在sequence中使用p_sequencer.vif的形式引用:
1
2
3
4
5
6
7
8
9
|
virtual task body();
my_transaction heartbeat_tr;
while(1) begin
repeat(10000) @(posedge p_sequencer.vif.clk);
grab();
`uvm_do(heartbeat_tr)
ungrab();
end
endtask
|
一个driver除了发送心跳包之外, 它还会发送一些其他包。 这就意味着要在这个driver相应的sequener上启动多个sequence。 在这些sequence产生的transaction中, 心跳包优先级较高, 当前正在发送的包在发送完成后应该立即发送心跳包, 所以在上述 sequence中应使用grab功能。
如果使用virtual sequence启动此sequence, 需要使用fork join_none的方式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
文件: src/ch10/section10.3/10.3.1/my_case0.sv
class case0_vseq extends uvm_sequence #(my_transaction);
…
virtual task body();
case0_sequence normal_seq;
heartbeat_sequence heartbeat_seq;
heartbeat_seq = new("heartbeat_seq");
heartbeat_seq.starting_phase = this.starting_phase;
fork
heartbeat_seq.start(p_sequencer.p_sqr);
join_none
`uvm_do_on(normal_seq, p_sequencer.p_sqr)
endtask
…
endclass
|
normal_seq为另外一个启动的sequence, 不能使用如下的方式启动:
1
2
3
4
5
6
7
8
|
virtual task body();
case0_sequence normal_seq;
heartbeat_sequence heartbeat_seq;
fork
`uvm_do_on(heartbeat_seq, p_sequencer.p_sqr)
`uvm_do_on(normal_seq, p_sequencer.p_sqr)
join
endtask
|
因为心跳sequence是无限循环的。 上述的启动方式会导致整个body无法停止。
使用fork join_none的形式启动心跳sequence的一个问题是driver可能正在发送一个心跳包, 但是此时virtual_sequence的objection
被撤销了, main_phase停止, 退出仿真。 在某些DUT的实现中, 这种只发送了一半的包是不允许的, 可能会导致最终检查结果异
常。 为了避免这种情况的出现, 在心跳sequence中要发送transaction前raise objection, 在发送完后drop objection:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
文件: src/ch10/section10.3/10.3.1/my_case0.sv
class heartbeat_sequence extends uvm_sequence #(my_transaction);
…
virtual task body();
my_transaction heartbeat_tr;
while(1) begin
repeat(100) @(posedge p_sequencer.vif.clk);
grab();
starting_phase.raise_objection(this);
`uvm_do_with(heartbeat_tr, {heartbeat_tr.pload.size == 50;})
`uvm_info("hb_seq", "this is a heartbeat transaction", UVM_MEDIUM)
starting_phase.drop_objection(this);
ungrab();
end
endtask
…
endclass
|
这种方式在启动的时候要谨记如代码 所示给此心跳sequence的starting_phase赋值。 如果不使用手工方式启动此sequence, 也可以使用default_sequence的方式启动。 此时相当于my_sequencer上以两种不同的方式启动了两个sequence: 一是以default_sequence的形式启动, 二是在virtual_sequence中启动 。
无论在sequence还是在driver中实现心跳包的功能, 都是完全可以的。 由于心跳包需要和另外的包竞争driver, 所以如果使用 driver实现心跳包, 则需要手工实现这种仲裁功能。 而如果在sequence中实现, 则由于UVM的sequence机制天生具有仲裁的功能, 用户可以省略仲裁的代码。
在sequence中实现的另一个好处是可以更加容易地控制心跳频率的改变。
例如测试一个心跳包异常的测试用例, 使其每隔5个心跳包少发一个心跳包, 此时只需要重写一个sequence即可。 这个新的sequence对老的心跳sequence没有任何影响, 同时也不需要 对driver进行任何变更。sequence与driver共同组合起来用于控制激励源的发送。 当要控制某种特定激励源的发送时, 这种控制功能既可以由driver实现, 也可以由sequence实现。
在某些情况下, 可以将driver的一些行为移到sequence中实现, 这会使得验证平台的编写更加简单。UVM提供了强大的灵活性, 同样的一件事情可以使用多种方式实现。
只将virtual_sequence设置为default_sequence
config_db机制最大的问题在于其set函数的第二个参数是一个字符串, 而UVM本身不对这个字符串所代表的路径是否有效做任何检查。 这会导致一些莫名其妙的问题。
如在env中使用如下的代码实例化bus_agt:
1
2
3
4
5
6
|
virtual function void build_phase(uvm_phase phase);
super.build_phase(phase);
bus_agt = bus_agent::type_id::create("bus_agt", this);
i_agt = my_agent::type_id::create ("i_agt ", this);
…
endfunction
|
这个实例化不存在任何问题, 并且充分考虑到了代码的美观性, 对双引号进行了对齐。 在某个测试用例中, 可以使用如下的方式分别为他们设置default_sequence:
1
2
3
4
5
|
function void my_case0::build_phase(uvm_phase phase);
super.build_phase(phase);
uvm_config_db#(uvm_object_wrapper)::set(this, "env.i_agt.sqr.main_phase", "default_sequence", case0_seq::type_id::get());
uvm_config_db#(uvm_object_wrapper)::set(this, "env.bus_agt.sqr.main_phase", "default_sequence", case0_bus_seq::type_id::get());
endfunction
|
运行上述测试用例, 发现bus_agt的sequencer上设置的default_sequence启动了, 但是i_agt的sequencer上设置的default_sequence 则没有启动。 这是为什么?
这个bug非常隐蔽。 当将bus_agt和i_agt实例化的时候, 为了美观, 在i_agt的名字后加了空格, 而UVM将双引号之间的字符串都当做i_agt的名字。
假如在i_agt.sqr中调用get_full_name函数, 那么得到的结果如下:
1
|
uvm_test_top.env.i_agt .sqr
|
可以很清晰地看到空格是名字的一部分 。 这种bug让人防不胜防, 如果运气好, 可能马上就会发现这个bug, 但是如果不好,可能要一两个小时才能发现。 或许会有读者说, 这一切都是由代码美观引起的。 其实代码美观本身并没有错, 并不能因为这一处小小的bug而放弃对代码美观的追求。
真正的问题还在于config_db机制不对set函数的第二个参数提供检查。 当config_db::set用的越多, 这种bug出现的机率也就越大。
因此, 应该尽量避免config_db::set的使用。 在本节中, 即尽量少设置default_sequence, 只将virtual sequence设置为 default_sequence。
如果只将virtual sequence设置为default_sequence, 那么所有其他的sequence都在其中启动。 其中带来的一个好处是向sequence 传递参数更加方便。 在sequence中可以使用config_db机制来获取运行所需要的参数。 上面已经见识过config_db机制可能带来的隐患。 如果使用virtual sequence启动一个sequence, 那么可以使用如下的方式为其赋值:
1
2
3
4
5
6
7
8
|
class case_vseq extends uvm_sequence;
virtual task body();
normal_seq nseq;
nseq = new();
nseq.xxx = yyy;
nseq.start(p_sequencer.p_sqr)
endtask
endclass
|
这在很大程度上避免了config_db的字符串引出的问题。
disable fork语句对原子操作的影响
在网络通信系统中有各种各样的计数器。 通常来说, 这些计数器的类型是W1C, 即写1清零。 由于是W1C, 那么对于这个计数器来说, 就存在如下的情况: 总线正在对其进行写清操作, 同时DUT内部正在累加此计数器。 在这种极端情况下, 可能会导致计数器计数错误或者直接挂起, 后续完全无法再正常计数。 因此需要对这种情况做测试。
在virtual sequence中开启如下两个进程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
class caw_vseq extends uvm_sequence;
caw_seq demo_s;
logic[31:0] rdata;
virtual task body();
uvm_status_e status;
if(starting_phase != null)
starting_phase.raise_objection(this);
demo_s = caw_seq::type_id::create("demo_s");
fork
begin
demo_s.start(p_sequencer.p_cp_sqr);
end
while(1) begin
p_sequencer.p_rm.counter.write(status, 1, UVM_FRONTDOOR);
end
join_any
disable fork;
p_sequencer.p_rm.counter.read(status, rdata, UVM_FRONTDOOR);
demo_s.start(p_sequencer.p_cp_sqr);
p_sequencer.p_rm.counter.read(status, rdata, UVM_FRONTDOOR);
if(starting_phase != null)
starting_phase.drop_objection(this);
endtask
endclass
|
上述代码看似解决了问题, 但是出现了一个新的情况是程序无法终止。 在此测试用例中, 在运行disable fork语句之后读取计数器时, 会发现此寄存器正在写, 于是一直等待。 究其原因在于UVM的寄存器模型的write操作是原子操作, 如果只是使用disable fork语句野蛮地终止, 那么此原子操作尚未完成, 于是虽然进程终止了, 但是其中的一些原子操作标志位并没有清除, 从而出现错误。
正确的解决方法是:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
class caw_vseq extends uvm_sequence;
caw_seq demo_s;
semaphore m_atomic = new(1); // 信号, 是原子操作
logic [31:0] rdata;
virtual task body();
uvm_status_e status;
if(starting_phase != null)
starting_phase.raise_objection(this);
demo_s = caw_seq::type_id::create("demo_s");
fork
begin
demo_s.start(p_sequencer.p_cp_sqr);
m_atomic.get(1); //
end
while(1) begin
if(m_atomic.try_get(1)) begin // get 完之后 m_atomic 为0 下次再get 就 get 不到了
p_sequencer.p_rm.counter.write(status, 1, UVM_FRONTDOOR);
m_atomic.put(1); // 如果 m_atomic 为0 put 之后 m_atomic 为1 猜测如果m_atomic 为1 则put(1) 之后 m_atomic 为 2
end
else begin
break;
end
end
join
p_sequencer.p_rm.counter.read(status, rdata, UVM_FRONTDOOR);
demo_s.start(p_sequencer.p_cp_sqr);
p_sequencer.p_rm.counter.read(status, rdata, UVM_FRONTDOOR);
if(starting_phase != null)
starting_phase.drop_objection(this);
endtask
endclass
|
通过使用semaphore, 每次写counter寄存器之前都会试图从semaphore中得到一个键值, 如果无法得到, 则表示另外一个进程( demo_s进程) 已经执行完毕, 此时while循环也没有必要进行下去, 直接终止。
DUT参数的随机化
验证中有两大问题: 一是向DUT灌输不同的激励, 二是为DUT配置不同的参数。
使用寄存器模型随机化参数
使用寄存器模型的随机化及update来为DUT选择一组随机化的参数:
1
2
|
assert(p_rm.randomize());
p_rm.updata(status, UVM_FRONTDOOR);
|
上述方式随机化出来的参数可能是任意组合。 但是, 在很多情况下用户希望的是一种特定的组合。 如对于一个压缩算法来说, 它可以有有损压缩、 无损压缩及不压缩三种模式。 在建立测试用例时, 需要为这个算法模块至少建立四个测试用例: 有损压缩的、 无损压缩的、 不压缩的及以上三种随机组合的。 在建立前三个测试用例时, 需要将参数随机化的范围缩小。
如何缩小随机化的范围? 这里提供三种方式:
一是只将需要随机化的寄存器调用randomize函数, 其他不调用。 在调用时指定约束:
1
2
|
assert(p_rm.reg1.randomize() with { reg_data.value == 5'h3;});
assert(p_rm.reg2.randomize() with { reg_data.value >= 7'h9;});
|
二是在调用整体的randomize函数时, 为需要指定参数的寄存器指定约束:
1
|
assert(p_rm.randomize() with {reg1.reg_data.value == 5'h3; reg2.reg_data.value >= 7'h9});
|
第三种方式则是借助于factory机制的重载功能, 从需要随机的寄存器中派生一个新的类, 在新的类中指定约束, 最后再使用重载替换掉原先寄存器模型中相应的寄存器:
1
2
3
4
5
6
7
8
9
10
|
class dreg1 extends my_reg1;
constraint{
reg_data.value == 5'h3;
}
endclass
class dreg2 extends my_reg2;
constraint{
reg_data.value >= 7'h9;
}
endclass
|
使用单独的参数类
上面提供了使用寄存器模型来随机化DUT参数的方式。 考虑需要一种跨越寄存器的约束, 如需要寄存器a中的field0的值与寄存器b中field0的值的和大于100。 上面介绍的三种方式中, 只有第二种能够实现:
1
|
assert(p_rm.randomize() with {rega.field0.value + regb.field0.value >=100;});
|
由于这个约束对所有的测试用例都适用, 因此期望它能够写在寄存器模型的constraint里:
1
2
3
4
5
|
class reg_model extends uvm_reg_block;
constraint reg_ab_cons{
rega.field0.value + regb.field0.value >=100;
}
endclass
|
对于寄存器模型来说, 如果这个寄存器模型是自己手工创建的, 那么在其中加入constraint没有任何问题。 但是通常来说, 在IC公司中, 寄存器模型都是由一些脚本命令自动创建的。 在一个验证平台中, 需要用到寄存器的地方有如下三个, 一是RTL代码中, 二是SystemVerilog中, 三是C语言中。 必须时刻保持这三处的寄存器完全一致。 当一处有更新时, 其他两处必须相应更新。 寄存器成百上千个, 如果全部手工来做这些事情, 将会非常耗费时间和精力。 因此一般的IC公司会将寄存器的描述放在一个源文件中, 如word文档、 excel文件、 xml文档中, 然后使用脚本从中提取寄存器信息, 并分别生成相应的RTL代码、 UVM中的寄存器模型及C语言中的寄存器模型。 当寄存器更新时, 只更新源文件即可, 其他的可以自动更新。 这种方式省时省力, 是主流的方式。
在使用脚本创建寄存器模型的情况下, 在寄存器模型中加入constraint就比较困难。 因为很难在源文件( 如word文档等) 中描述约束, 尤其是存在跨寄存器的约束时。 所以有很多生成寄存器模型的工具并不支持约束。
为了解决这个问题, 可以针对DUT中需要随机化的参数建立一个dut_parm类, 并在其中指定默认约束:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
文件: src/ch10/section10.4/10.4.2/dut_parm.sv
class dut_parm extends uvm_object;
reg_model p_rm;
…
rand bit[15:0] a_field0;
rand bit [15:0] b_field0;
constraint ab_field_cons{
a_field0 + b_field0 >= 100;
}
task update_reg();
p_rm.rega.write(status, a_field0, UVM_FROTDOOR);
p_rm.regb.write(status, b_field0, UVM_FROTDOOR);
endtask
endclass
|
这段代码中指定了一个update_reg任务, 它用于当参数随机化完成后, 把相关的参数更新到DUT中。
在virtual sequence中, 可以实例化这个新的类, 随机化并调用update_reg任务:
1
2
3
4
5
6
7
8
9
10
11
12
|
文件: src/ch10/section10.4/10.4.2/my_case0.sv
class case0_cfg_vseq extends uvm_sequence;
…
virtual task body();
dut_parm pm;
pm = new("pm");
assert(pm.randomize());
pm.p_rm = p_sequencer.p_rm;
pm.update_reg();
endtask
…
endclass
|
这种专门的参数类的形式在跨寄存器的约束较多时特别有用。
聚合参数
聚合参数的定义
在验证平台中用到的参数有两大类:
- 一类是验证环境与DUT中都要用到的参数, 这些参数通常都对应DUT中的寄存器, 如使用单独的参数类 中已经将这些参数组织成了一个参数类;
- 另外一类是验证环境中独有的, 比如driver中要发送的preamble数量的上限和下限。
对于一个大的项目来说, 要配置的参数可能有千百个。 如果全部使用config_db的写法, 那么就会出现下面这种情况:
1
2
3
4
5
6
7
8
|
classs base_test extends uvm_test;
function void build_phase(uvm_phase phase);
super.build_phase(phase);
uvm_config_db#(int)::set(this, "path1", "var1", 7);
…
uvm_config_db#(int)::set(this, "path1000", "var1000", 999);
endfunction
endclass
|
可以想像, 这1000句set函数写下来将会是多么壮观的一件事情。 但是壮观的同时也显示出了这是多么麻烦的一件事情。
一种比较好的方法就是将这1000个变量放在一个专门的类里面来实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
class my_config extends uvm_object;
rand int var1;
…
rand int var1000;
constraint default_cons{
var1 = 7;
…
var1000 = 999;
}
`uvm_object_utils_begin(my_config)
`uvm_field_int(var1, UVM_ALL_ON)
…
`uvm_field_int(var1000, UVM_ALL_ON)
`uvm_object_utils_end
endclass
|
经过上述定义之后, 可以在base_test中这样写:
1
2
3
4
5
6
7
8
9
10
|
classs base_test extends uvm_test;
my_config cfg;
function void build_phase(uvm_phase phase);
super.build_phase(phase);
cfg = my_config::type_id::create("cfg");
uvm_config_db#(my_config)::set(this, "env.i_agt.drv", "cfg", cfg);
uvm_config_db#(my_config)::set(this, "env.i_agt.mon", "cfg", cfg);
…
endfunction
endclass
|
这样, 省略了绝大多数的set语句。 在driver中以如下的方式使用这个聚合参数类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
class my_driver extends uvm_driver#(my_transaction);
my_config cfg;
`uvm_component_utils_begin(my_driver)
`uvm_field_object(cfg, UVM_ALL_ON | UVM_REFERENCE)
`uvm_component_utils_end
extern task main_phase(uvm_phase phase);
endclass
task my_driver::main_phase(uvm_phase phase);
while(1) begin
seq_item_port.get_next_item(req);
pre_num = $urand_range(cfg.pre_num_min, cfg.pre_num_max);
…//drive this pkt, and the number of preamble is pre_num
seq_item_port.item_done();
end
endtask
|
如果在某个测试用例中想要改变某个变量的值, 可以这样做:
1
2
3
4
5
6
7
8
|
class case100 extends base_test;
function void build_phase(uvm_phase phase);
super.build_phase(phase);
cfg.pre_num_max = 100;
cfg.pre_num_min = 8;
…
endfunction
endclass
|
聚合参数的优势与问题
使用聚合参数后, 可以将此参数类的指针放在virtual sequencer中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
class my_vsqr extends uvm_sequencer;
my_config cfg;
…
endclass
class base_test extends uvm_test;
my_config cfg;
my_vsqr vsqr;
function void build_phase(uvm_phase phase);
super.build_phase(phase);
cfg = my_config::type_id::create("cfg");
vsqr = my_vsqr::type_id::create("vsqr", this);
vsqr.cfg = this.cfg;
…
endfunction
endclass
|
这样, 当sequence要动态地改变某个验证平台中的变量值时, 可以使用如下的方式:
1
2
3
4
5
6
7
8
9
|
class vseq extends uvm_sequence;
`uvm_object_utils(vseq)
`uvm_declare_p_sequencer(vsequencer)
task body();
…//send some transaction
p_sequencer.cfg.pre_num_max = 99;
…//send other transaction
endtask
endclass
|
聚合参数方便了在sequence中改变验证平台参数。 在某些情况下, 甚至可以将interface也放入此聚合参数类中:
1
2
3
4
5
6
7
8
9
10
11
|
文件: src/ch10/section10.5/10.5.2/my_config.sv
class my_config extends uvm_object;
`uvm_object_utils(my_config)
virtual my_if vif;
function new(string name = "my_config");
super.new(name);
$display("%s", get_full_name());
if(!uvm_config_db#(virtual my_if)::get(null, get_full_name(), "vif", vif))
`uvm_fatal("my_config", "please set interface")
endfunction
endclass
|
这样, 无论是在driver中还是monitor中, 都可以直接使用cfg.vif, 而不必再使用config_db来得到interface:
1
2
3
4
5
6
7
8
|
文件: src/ch10/section10.5/10.5.2/my_driver.sv
task my_driver::main_phase(uvm_phase phase);
cfg.vif.data <= 8'b0;
cfg.vif.valid <= 1'b0;
while(!cfg.vif.rst_n)
@(posedge cfg.vif.clk);
…
endtask
|
同样的, 如果将这个cfg的指针赋值给普通的sequencer, 那么在10.3.1节中心跳sequence的实现中, sequencer也不必再使用uvm_config_db::get得到接口。
在 中, 使用config_db的形式得到vif。 这里出现了 uvm_config_db::get() , 由于my_config是一个object, 而不
是component, 所以 get_full_name 得到的结果是其实例化时指定的名字。 所以, base_test中实例化cfg的名字要与top_tb中
config_db::set的路径参数一致。 如:
1
2
3
4
5
6
7
8
9
10
|
function void base_test::build_phase(uvm_phase phase);
…
cfg = new("cfg");
endfunction
module top_tb;
…
initial begin
uvm_config_db#(virtual my_if)::set(null, "cfg", "vif", input_if);
end
endmodule
|
或者:
1
2
3
4
5
6
7
8
9
10
|
function void base_test::build_phase(uvm_phase phase);
…
cfg = new({get_full_name(), ".cfg"});
endfunction
module top_tb;
…
initial begin
uvm_config_db#(virtual my_if)::set(null, "uvm_test_top.cfg", "vif", input_if);
end
endmodule
|
其实, 这里最方便的还是使用直接赋值的形式。 在top_tb中将interface通过config_db::set的方式传递给base_test, 在base_test 中实例化cfg后就可以直接赋值:
1
2
3
4
5
|
function void base_test::build_phase(uvm_phase phase);
…
cfg = new("cfg");
cfg.vif = this.vif.
endfunction
|
这种将所有参数聚合起来的做法可以大大方便验证平台的搭建。 将这个聚合类的指针赋值给任意component, 这样这些 component再也不需要使用config_db::get函数来获取参数了。 当验证平台的某个组件( 如driver) 要增加一个参数时, 只需要在 这个聚合类中加入此参数, 在测试用例中直接为其赋值, 然后在验证平台( 如driver) 中就可以直接使用:
1
2
3
4
5
6
7
8
9
10
11
12
|
class my_config extends uvm_object;
rand int new_var;
…
endclass
function void my_case0::build_phase(uvm_phase phase);
…
cfg.new_var = 1;
endfunction
task my_driver::main_phase(uvm_phase phase);
if(cfg.new_var)
…
endtask
|
假如不使用聚合类, 而使用config_db, 那么需要在测试用例中进行设置:
1
2
3
4
|
function void my_case0::build_phase(uvm_phase phase);
…
uvm_config_db#(int)::set(this, "uvm_test_top.env.i_agt.drv", "new_var", 1);
endfunction
|
在driver中增加一个变量, 并且使用get语句获取它:
1
2
3
4
5
6
7
8
|
function void my_driver::build_phase(uvm_phase phase);
…
void'(uvm_config_db#(int)::get(this, "", "new_var", new_var);
endfunction
task my_driver::main_phase(uvm_phase phase);
if(new_var)
…
endtask
|
可以看出使用聚合类减少了config_db::set的使用, 也会大大降低出错的概率。 不过聚合参数也不是完美的。 聚合参数的本质上是将一些属于某个uvm_component的变量变成对所有的uvm_component可见, 从而使得这些变量错误地被其他uvm_component修改。
另外, 聚合参数整合了整个验证平台的参数, 这在一定程度上降低了验证平台的可重用性。聚合参数类对于env 级别的重用没有任何问题。 但是在实际中, 能够做到env级别重用的IC公司并不多。 很多公司使用的是基于agent的 重用。 假如某个agent中需要的参数只占据聚合参数类的10%的参数, 现在这个agent被其他项目重用, 那么在新的项目中也需要实例化这个聚合参数类。但是在新的项目中,这个聚合参数类其中可能90%的参数是无用的。解决这个问题的方式是缩小聚合参数的粒度, 将一个聚合参数类分成多个小的聚合参数类, 如将agent的所有的参数定义为一个聚合参数类, 在大的聚合参数类中实例 化这个小的聚合参数类。 只是这样一来, 可能每个聚合参数类中只有一两个参数。 与直接使用config_db相比, 并没有方便多少。
config_db
换一个phase使用config_db
在前面的例子中, 使用config_db几乎都是在build_phase中。 由于其config_db::set的第二个参数是字符串, 所以经常出错。 一个component的路径可以通过get_full_name() 来获得。 要想避免config_db::set第二个参数引起的问题, 一种可行的想法是把这个参数使用get_full_name()。 如在测试用例中对driver中某个参数进行设置:
1
|
uvm_config_db#(int)::set(null, env.i_agt.drv.get_full_name(), "pre_num", 100);
|
若要对sequence的某个参数设置, 可以:
1
|
uvm_config_db#(int)::set(null, {env.i_agt.sqr.get_full_name(), ".*"}, "pre_num", 100);
|
但是在build_phase时, 整棵UVM树还没有形成, 使用env.i_agt.drv的形式进行引用会引起空指针的错误。
所以, 要想在config_db::set() 中使用get_full_name(), 有两种方法:
一种是所有的实例化工作都在各自的new函数中完成:
1
2
3
4
5
6
7
8
9
10
11
|
function base_test::new(string name, uvm_component parent);
super.new(name, parent);
env = my_env::type_id::create("env", this);
endfunction
function my_env::new(string name, uvm_component parent);
super.new(name, parent);
i_agt = my_agent::type_id::create("i_agt", this);
o_agt = my_agent::type_id::create("o_agt", this);
…
endfunction
…
|
在这种情况下, 当整个验证平台运行到build_phase时, UVM树已经实例化完毕, 在uvm_confg_db::set中使用get_full_name 没有任何问题。
第二种方式是将uvm_config_db::set移到connect_phase中去。
由于connect_phase是由下向上执行的, base_test( 或者测试用例) 的connect_phase几乎是最后执行的, 因此应该在end_of_elaboration_phase或者start_of_simulation_phase调用uvm_config_db::get。
1
2
3
4
5
6
|
function void my_case0::connect_phase(uvm_phase phase);
uvm_config_db#(int)::set(null, env.i_agt.drv.get_full_name();, "pre_num", 100);
endfunction
function void my_driver::end_of_elaboration_phase(uvm_phase phase);
void'(uvm_config_db#(int)::get(this, "", "pre_num", pre_num));
endfunction
|
以上介绍的两种方式, 都对top_tb中的config_db::set无效, 因为在top_tb中都很难使用类似env.i_agt.sqr.get_full_name() 的方式来获得一个路径值。 幸运的是, top_tb中的config_db::set语句不多, 且它们相对比较固定, 通常不会出问题。
config_db的替代者
config_db 设置结构性的参数
config_db设置的参数有两种, 一种是结构性的参数, 如控制driver是否实例化的参数is_active:
1
2
3
4
5
6
7
8
|
function void my_agent::build_phase(uvm_phase phase);
super.build_phase(phase);
if (is_active == UVM_ACTIVE) begin
sqr = my_sequencer::type_id::create("sqr", this);
drv = my_driver::type_id::create("drv", this);
end
mon = my_monitor::type_id::create("mon", this);
endfunction
|
对于这种参数, 可以在实例化agent时同时指明其is_active的值:
1
2
3
4
5
6
7
8
|
virtual function void build_phase(uvm_phase phase);
super.build_phase(phase);
if(!in_chip) begin
i_agt = my_agent::type_id::create("i_agt", this);
i_agt.is_active = UVM_ACTIVE;
end
…
endfunction
|
config_db 设置非结构性的参数
对于在build_phase中设置的一些非结构性的参数, 如向某个driver中传递某个参数:
1
|
uvm_config_db#(int)::set(this, "env.i_agt.drv", "pre_num", 100);
|
可以完全在build_phase之后的任意phase中使用绝对路径引用进行设置:
1
2
3
|
function void my_case0::connect_phase(uvm_phase phase);
env.i_agt.drv.pre_num = 100;
endfunction
|
对于那些向sequence中传递的参数, 如 只将virtual_sequence设置为default_sequence 所示, 可以在virtual sequence中启动sequence, 并通过赋值的方式传递。
但是这样的前提是virtual sequence已经启动。 那么如何启动virtual sequence呢? 可以通过 default_sequence来启动的:
1
2
3
4
|
function void my_case0::build_phase(uvm_phase phase);
super.build_phase(phase);
uvm_config_db#(uvm_object_wrapper)::set(this, "v_sqr.main_phase", "default_sequence", case0_vseq::type_id::get());
endfunction
|
但是其实可以在测试用例的main_phase中手工启动此sequence:
1
2
3
4
5
6
7
|
task my_case0::main_phase(uvm_phase phase);
case0_vseq vseq;
super.main_phase(phase);
vseq = new("vseq");
vseq.starting_phase = phase;
vseq.start(vsqr);
endtask
|
这样可以不用再在build_phase中设置default_sequence。
通过绝对路径引用赋值
可以通过uvm_root::get() 得到UVM树真正的根uvm_top, 从uvm_top的孩子中找到base_test( 大多数情况下uvm_top只有一个名字为uvm_test_top的孩子, 不过也不能排除有多个孩子的情况) 的实例,并通过绝对路径引用赋值:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
文件: src/ch10/section10.6/10.6.2/my_case0.sv
class case0_vseq extends uvm_sequence;
…
virtual task body();
my_transaction tr;
drv0_seq seq0;
drv1_seq seq1;
base_test test_top;
uvm_component children[$];
uvm_top.get_children(children);
foreach(children[i]) begin
if($cast(test_top, children[i])) ; // children[i] 转换成 base_test 类型
end
if(test_top == null)
`uvm_fatal("case0_vseq", "can't find base_test 's instance")
fork
`uvm_do_on(seq0, p_sequencer.p_sqr0);
`uvm_do_on(seq1, p_sequencer.p_sqr1);
begin
#10000;
//uvm_config_db#(bit)::set(uvm_root::get(), "uvm_test_top.env0.scb", "cmp_en", 0);
test_top.env0.scb.cmp_en = 0;
#10000;
//uvm_config_db#(bit)::set(uvm_root::get(), "uvm_test_top.env0.scb", "cmp_en", 1);
test_top.env0.scb.cmp_en = 1;
end
join
#100;
endtask
endclass
|
至于在top_tb中使用config_db对interface进行的传递, 可以使用绝对路径的方式:
1
2
3
4
|
function void base_test::connect_phase(uvm_phase phase);
env0.i_agt.drv.vif = testbench.input_if0;
…
endfunction
|
通过静态变量来实现赋值
如果不使用绝对路径, 可以通过静态变量来实现。 新建一个类, 将此验证平台中所有可能用到的 interface放入此类中作为成员变量:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
文件: src/ch10/section10.6/10.6.2/if_object.sv
class if_object extends uvm_object;
…
static if_object me;
static function if_object get();
if(me == null) begin
me = new("me");
end
return me;
endfunction
virtual my_if input_vif0;
virtual my_if output_vif0;
virtual my_if input_vif1;
virtual my_if output_vif1;
endclass
|
在top_tb中为这个类的interface赋值:
1
2
3
4
5
6
7
8
9
10
11
12
|
文件: src/ch10/section10.6/10.6.2/top_tb.sv
module top_tb;
…
initial begin
if_object if_obj;
if_obj = if_object::get();
if_obj.input_vif0 = input_if0;
if_obj.input_vif1 = input_if1;
if_obj.output_vif0 = output_if0;
if_obj.output_vif1 = output_if1;
end
endmodule
|
get函数是if_object的一个静态函数, 通过它可以得到if_object的一个实例, 并对此实例中的interface进行赋值。 在base_test的connect_phase( 或build_phase之后的其他任一phase) 对所有的interface进行赋值:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
文件: src/ch10/section10.6/10.6.2/base_test.sv
function void base_test::connect_phase(uvm_phase phase);
if_object if_obj;
if_obj = if_object::get();
v_sqr.p_sqr0 = env0.i_agt.sqr;
v_sqr.p_sqr1 = env1.i_agt.sqr;
env0.i_agt.drv.vif = if_obj.input_vif0;
env0.i_agt.mon.vif = if_obj.input_vif0;
env0.o_agt.mon.vif = if_obj.output_vif0;
env1.i_agt.drv.vif = if_obj.input_vif1;
env1.i_agt.mon.vif = if_obj.input_vif1;
env1.o_agt.mon.vif = if_obj.output_vif1;
endfunction
|
使用上述方式, 可以在验证平台中完全避免config_db的使用。
set函数的第二个参数的检查
无论如何, config_db机制是UVM中一项重要的机制, 上节那样完全地不用config_db是走向了另外一个极端。 config_db机制的最大问题在于不对set函数的第二个参数进行检查。 本节介绍一个函数, 可以在一定程度上( 并不能检查所有! ) 实现对第二个参数有效性的检查。 读者可以将这个函数加入到自己的验证平台中
函数的代码如下:
1
2
3
4
|
文件: src/ch10/section10.6/10.6.3/check_config.sv
function void check_all_config();
check_config::check_all();
endfunction
|
这个全局函数会调用check_config的静态函数check_all:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
文件: src/ch10/section10.6/10.6.3/check_config.sv
static function void check_all();
uvm_component c;
uvm_resource_pool rp;
uvm_resource_types::rsrc_q_t rq;
uvm_resource_types::rsrc_q_t q;
uvm_resource_base r;
uvm_resource_types::access_t a;
uvm_line_printer printer;
c = uvm_root::get();
if(!is_inited)
init_uvm_nodes(c);
rp = uvm_resource_pool::get();
q = new;
printer=new();
foreach(rp.rtab[name]) begin // 把 rp.rtab 里的元素遍历到 name 里
rq = rp.rtab[name];
for(int i = 0; i < rq.size(); ++i) begin
r = rq.get(i);
//$display("r.scope = %s", r.get_scope());
if(!path_reachable(r.get_scope)) begin
`uvm_error("check_config", "the following config_db::set's path is not reachable in your verification environment, please check")
r.print(printer);
r.print_accessors();
end
end
end
endfunction
|
这个函数先根据is_inited的值来调用init_nodes函数, 将uvm_nodes联合数组初始化。 is_inited和uvm_nodes是check_config的两个静态成员变量 :
1
2
3
4
|
文件: src/ch10/section10.6/10.6.3/check_config.sv
class check_config extends uvm_object;
static uvm_component uvm_nodes[string];
static bit is_inited = 0;
|
在init_nodes函数中使用递归的方式遍历整棵UVM树, 并将树上所有的结点加入到uvm_nodes中。 uvm_nodes的索引是相应结点的get_full_name的值, 而存放的值就是相应结点的指针:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
文件: src/ch10/section10.6/10.6.3/check_config.sv
static function void init_uvm_nodes(uvm_component c);
uvm_component children[$];
string cname;
uvm_component cn;
uvm_sequencer_base sqr;
is_inited = 1;
if(c != uvm_root::get()) begin
cname = c.get_full_name();
uvm_nodes[cname] = c;
if($cast(sqr, c)) begin // 强制类型转换 c 的类型 转换成 sqr 对应的 uvm_sequencer_base类型
string tmp;
$sformat(tmp, "%s.pre_reset_phase", cname);
uvm_nodes[tmp] = c;
…
$sformat(tmp, "%s.main_phase", cname);
uvm_nodes[tmp] = c;
…
$sformat(tmp, "%s.post_shutdown_phase", cname);
uvm_nodes[tmp] = c;
end
end
c.get_children(children);
while(children.size() > 0) begin
cn = children.pop_front();
init_uvm_nodes(cn);
end
endfunction
|
初始化的工作只进行一次。 当下一次调用此函数时将不会进行初始化。 在初始化完成后, check_all函数将会遍历config_db库中的所有记录。 对于任一条记录, 检查其路径参数, 并将这个参数与uvm_nodes中所有的路径参数对比, 如果能够匹配, 说明这条路径在验证平台中是可达的。 这里调用了 path_reachable 函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
文件: src/ch10/section10.6/10.6.3/check_config.sv
static function bit path_reachable(string scope);
bit err;
int match_num;
match_num = 0;
foreach(uvm_nodes[i]) begin
err = uvm_re_match(scope, i);
if(err) begin
//$display("not_match: name is %s, scope is %s", i, scope);
end
else begin
//$display("match: name is %s, scope is %s", i, scope);
match_num++;
end
end
return (match_num > 0);
endfunction
|
config_db::set的第二个参数支持通配符, 所以path_reachable通过调用uvm_re_match函数来检查路径是否匹配。
uvm_re_match是UVM实现的一个函数, 它能够检查两条路径是否一样。 当uvm_nodes遍历完成后, 如果匹配的数量为0, 说明路径根本不可达, 此时将会给出一个UVM_ERROR的提示。
在UVM中使用很多的是default_sequence的设置:
1
|
uvm_config_db#(uvm_object_wrapper)::set(this, "env.i_agt.sqr.main_phase", "default_sequence", case0_sequence::type_id::get());
|
在这个设置的第二个参数中出现了main_phase。 如果只是将sequencer的get_full_name的结果与这个路径相比, 那么path_reachable函数认为是不匹配的。 所以init_nodes函数对于sequencer在其中加入了对各个phase的支持。
由于要遍历整棵UVM树的结点, 所以这个check_all_config函数只能在build_phase之后才能被调用, 如connect_phase等。
当不匹配时, 它会给出一条UVM_ERROR的提示信息,
如: my_case0.sv 中
1
2
3
4
|
function void my_case0::build_phase(uvm_phase phase);
super.build_phase(phase);
uvm_config_db#(uvm_object_wrapper)::set(this, "env.i_agt.sqr.main_phase", "default_sequence", case0_sequence::type_id::get());
endfunction
|
运行后结果为:
1
2
3
4
5
6
7
8
9
10
11
|
UVM_INFO @ 0: reporter [RNTST] Running test my_case0...
UVM_INFO /mnt/hgfs/plh_work/example_uvm/puvm/src/ch10/section10.6/10.6.3/my_scoreboard.sv(40) @ 206900000: uvm_test_top.env.scb [my_scoreboard] Compare SUCCESSFULLY
UVM_INFO /mnt/hgfs/plh_work/example_uvm/puvm/src/ch10/section10.6/10.6.3/my_scoreboard.sv(40) @ 436100000: uvm_test_top.env.scb [my_scoreboard] Compare SUCCESSFULLY
UVM_INFO /mnt/hgfs/plh_work/example_uvm/puvm/src/ch10/section10.6/10.6.3/my_scoreboard.sv(40) @ 710900000: uvm_test_top.env.scb [my_scoreboard] Compare SUCCESSFULLY
UVM_INFO /mnt/hgfs/plh_work/example_uvm/puvm/src/ch10/section10.6/10.6.3/my_scoreboard.sv(40) @ 812300000: uvm_test_top.env.scb [my_scoreboard] Compare SUCCESSFULLY
UVM_INFO /mnt/hgfs/plh_work/example_uvm/puvm/src/ch10/section10.6/10.6.3/my_scoreboard.sv(40) @ 984700000: uvm_test_top.env.scb [my_scoreboard] Compare SUCCESSFULLY
UVM_INFO /mnt/hgfs/plh_work/example_uvm/puvm/src/ch10/section10.6/10.6.3/my_scoreboard.sv(40) @ 1224500000: uvm_test_top.env.scb [my_scoreboard] Compare SUCCESSFULLY
UVM_INFO /mnt/hgfs/plh_work/example_uvm/puvm/src/ch10/section10.6/10.6.3/my_scoreboard.sv(40) @ 1361300000: uvm_test_top.env.scb [my_scoreboard] Compare SUCCESSFULLY
UVM_INFO /mnt/hgfs/plh_work/example_uvm/puvm/src/ch10/section10.6/10.6.3/my_scoreboard.sv(40) @ 1452500000: uvm_test_top.env.scb [my_scoreboard] Compare SUCCESSFULLY
UVM_INFO /mnt/hgfs/plh_work/example_uvm/puvm/src/ch10/section10.6/10.6.3/my_scoreboard.sv(40) @ 1475100000: uvm_test_top.env.scb [my_scoreboard] Compare SUCCESSFULLY
TEST CASE PASSED
|
如果my_case0.sv 改为:
1
2
3
4
|
function void my_case0::build_phase(uvm_phase phase);
super.build_phase(phase);
uvm_config_db#(uvm_object_wrapper)::set(this, "env.i_agt .sqr.main_phase", "default_sequence", case0_sequence::type_id::get());
endfunction
|
即在 env.i_agt 后加了个空格, 那么结果为:
1
2
3
4
5
6
7
8
|
UVM_INFO @ 0: reporter [RNTST] Running test my_case0...
UVM_ERROR /mnt/hgfs/plh_work/example_uvm/puvm/src/ch10/section10.6/10.6.3/check_config.sv(101) @ 0: reporter [check_config] the following config_db::set's path is not reachable in your verification environment, please check
default_sequence [/^uvm_test_top\.env\.i_agt \.sqr\.main_phase$/] : (class uvm_pkg::uvm_object_wrapper) ?
default_sequence: (<unknown>@478) @478
--------
uvm_test_top reads: 0 @ 0 writes: 1 @ 0
UVM_FATAL @ 0: reporter [BUILDERR] stopping due to build errors
|
这个函数可以在很多地方调用。 如在sequence中使用config_db::set函数后, 就可以立即调用这个函数检查有效性。
需要说明的是, 这个函数有一些局限, 其中之一就是不支持config_db::set向object传递的参数, 如以下代码:
1
2
3
4
5
6
7
8
9
10
|
function void base_test::build_phase(uvm_phase phase);
…
cfg = new("cfg");
endfunction
module top_tb;
…
initial begin
uvm_config_db#(virtual my_if)::set(null, "cfg", "vif", input_if);
end
endmodule
|
和
1
2
3
4
5
6
7
8
9
10
11
|
function void base_test::build_phase(uvm_phase phase);
…
cfg = new({get_full_name(), ".cfg"});
endfunction
module top_tb;
…
initial begin
uvm_config_db#(virtual my_if)::set(null, "uvm_test_top.cfg", "vif", input_if);
end
endmodule
|
my_config传递virtual interface出现错误就不能通过这个函数检查出来。 幸运的是, 这种传递参数的方式并不多见, 出现错误的概率也比较低