Exercise 1
在本练习中,将为SimX周期级模拟器添加两个新的机器性能监控(MPM)计数器,用于计算内核执行后的GPU线程束效率。这两个计数器total_issued_warps(已发射线程束总数)和total_active_threads(活跃线程总数)将通过将活跃线程数除以GPU流水线中发射执行的线程束次数,来帮助您计算线程束效率。

以下补丁直接打到 8b10348e (minor update) 分支上即可
Exercise1_8b103_cf1a4.patch
|
|
解析
simx 的运行流程大概是这样的:
-
main.cpp => RT_CHECK(vx_start(device, krnl_buffer, args_buffer));
-
vx_start (runtime/stub/vortex.cpp ) => callbacks->start ( runtime/common/callbacks.inc )
-
start (vortex/runtime/simx/vortex.cpp) => processor_.run()
-
Processor::run() => ProcessorImpl::run() (vortex/sim/simx/processor.cpp)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21int ProcessorImpl::run() { SimPlatform::instance().reset(); this->reset(); bool done; int exitcode = 0; do { SimPlatform::instance().tick(); done = true; for (auto cluster : clusters_) { if (cluster->running()) { done = false; continue; } exitcode |= cluster->get_exitcode(); } perf_mem_latency_ += perf_mem_pending_reads_; } while (!done); return exitcode; } -
SimPlatform 里的方法的具体实现
- processor (vortex/sim/simx/processor.cpp) 中实例化 clusters_
1 2 3 4// create clusters for (uint32_t i = 0; i < arch.num_clusters(); ++i) { clusters_.at(i) = Cluster::Create(i, this, arch, dcrs_); }-
在 clusters (vortex/sim/simx/cluster.cpp) 中实例化 sockets_
-
在 sockets (vortex/sim/simx/socket.cpp) 中实例化 cores_
-
在core ( vortex/sim/simx/core.cpp ) 中实例化 SimObject实现 SimPlatform 的底层仿真实现
例如:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32void Core::tick() { this->commit(); this->execute(); this->issue(); this->decode(); this->fetch(); this->schedule(); ++perf_stats_.cycles; DPN(2, std::flush); } void Core::schedule() { auto trace = emulator_.step(); if (trace == nullptr) { ++perf_stats_.sched_idle; return; } // suspend warp until decode emulator_.suspend(trace->wid); DT(3, "pipeline-schedule: " << *trace); // advance to fetch stage fetch_latch_.push(trace); pending_instrs_.push_back(trace); // track active threads exercise 1 perf_stats_.total_issued_warps += 1; perf_stats_.total_active_threads += trace->tmask.count(); }
解题步骤
-
找到实现计算性能统计的地方
每次 vx_dev_close (vortex/runtime/stub/vortex.cpp) 都会执行 vx_dump_perf 这个函数已经实现了统计 VX_DCR_MPM_CLASS_CORE 和 VX_DCR_MPM_CLASS_MEM 的功能,
分析vx_dump_perf 可知, 只需要在仿真时传入命令行参数 –perf=xxx, 则xxx 就会赋值给 perf_class , 从而计算对应的MPM_CLASS
我们只需要添加一个 VX_DCR_MPM_CLASS_3 分支 来实现用于计算内核执行后的GPU线程束效率即可
-
添加定义获取性能统计变量的CSR 地址
按照 Exercise1_8b103_cf1a4.patch 的 modified: hw/rtl/VX_types.vh 修改
1 2 3 4 5 6 7// exercise 1 `define VX_CSR_MPM_TOTAL_ISSUED_WARPS 12'hB03 `define VX_CSR_MPM_TOTAL_ISSUED_WARPS_H 12'hB83 `define VX_CSR_MPM_TOTAL_ACTIVE_THREADS 12'hB04 `define VX_CSR_MPM_TOTAL_ACTIVE_THREADS_H 12'hB84 `define VX_DCR_MPM_CLASS_3 3已经有了
1 2 3`define VX_DCR_MPM_CLASS_NONE 0 `define VX_DCR_MPM_CLASS_CORE 1 `define VX_DCR_MPM_CLASS_MEM 2所以我们添加了一个
1`define VX_DCR_MPM_CLASS_3 3由 vortex/sim/simx/emulator.cpp 的 get_csr 函数中可知
1 2if ((addr >= VX_CSR_MPM_BASE && addr < (VX_CSR_MPM_BASE + 32)) || (addr >= VX_CSR_MPM_BASE_H && addr < (VX_CSR_MPM_BASE_H + 32))) {新定义的寄存器地址区间应该在 VX_CSR_MPM_BASE ~ (VX_CSR_MPM_BASE + 32) 和 VX_CSR_MPM_BASE_H ~ (VX_CSR_MPM_BASE_H + 32) 之间
-
找到统计性能的相关结构体并添加统计变量
搜索代码可以知道统计性能相关的结构体都在 PerfStats 里
按照 Exercise1_8b103_cf1a4.patch 的 modified: sim/simx/core.h 修改
-
添加统计性能的代码
由上面的分析可知, 每一个仿真步骤的最后都会运行 schedule 函数, 所以我们直接在 schedule 函数里面添加统计代码
按照 Exercise1_8b103_cf1a4.patch 的 modified: sim/simx/core.cpp 修改
-
完善 vx_dump_perf 函数
仿照 VX_DCR_MPM_CLASS_CORE 和 VX_DCR_MPM_CLASS_MEM 分支, 添加 case VX_DCR_MPM_CLASS_3 分支, 用于获取每个核的
total_issued_warps_per_core 和 total_active_threads_per_core 并计算每个核的warp_efficiency
把每个核的数据汇总成 total_active_threads 和 total_issued_warps 再计算总的效率
参考 Exercise1_8b103_cf1a4.patch 的 modified: runtime/stub/utils.cpp
-
完善get_csr 函数, 使得可以通过 csrr 命令访问定义的变量
按照 Exercise1_8b103_cf1a4.patch 的 modified: sim/simx/emulator.cpp 修改
在Exercise1 中, 内核运行结束后会调用 vx_perf_dump 通过 csr_read 即 csrr 命令把所有的 CSRS 写入到内存中, 在main 函数的 close_device 时就可以
调用 vx_mpm_query 通过 download 方法直接从内存读取对应的变量值了, 所以必须实现 get_csr 函数中获取 total_issued_warps_per_core 和 total_active_threads_per_core 的功能
调试技巧
如果 runtime/simx 目录下的代码有改动, 需要先进入 runtime/simx 执行 make clean 再 make 重新生成运行时的库
看日志文件可以使用 lnav, 看起来效率高一些
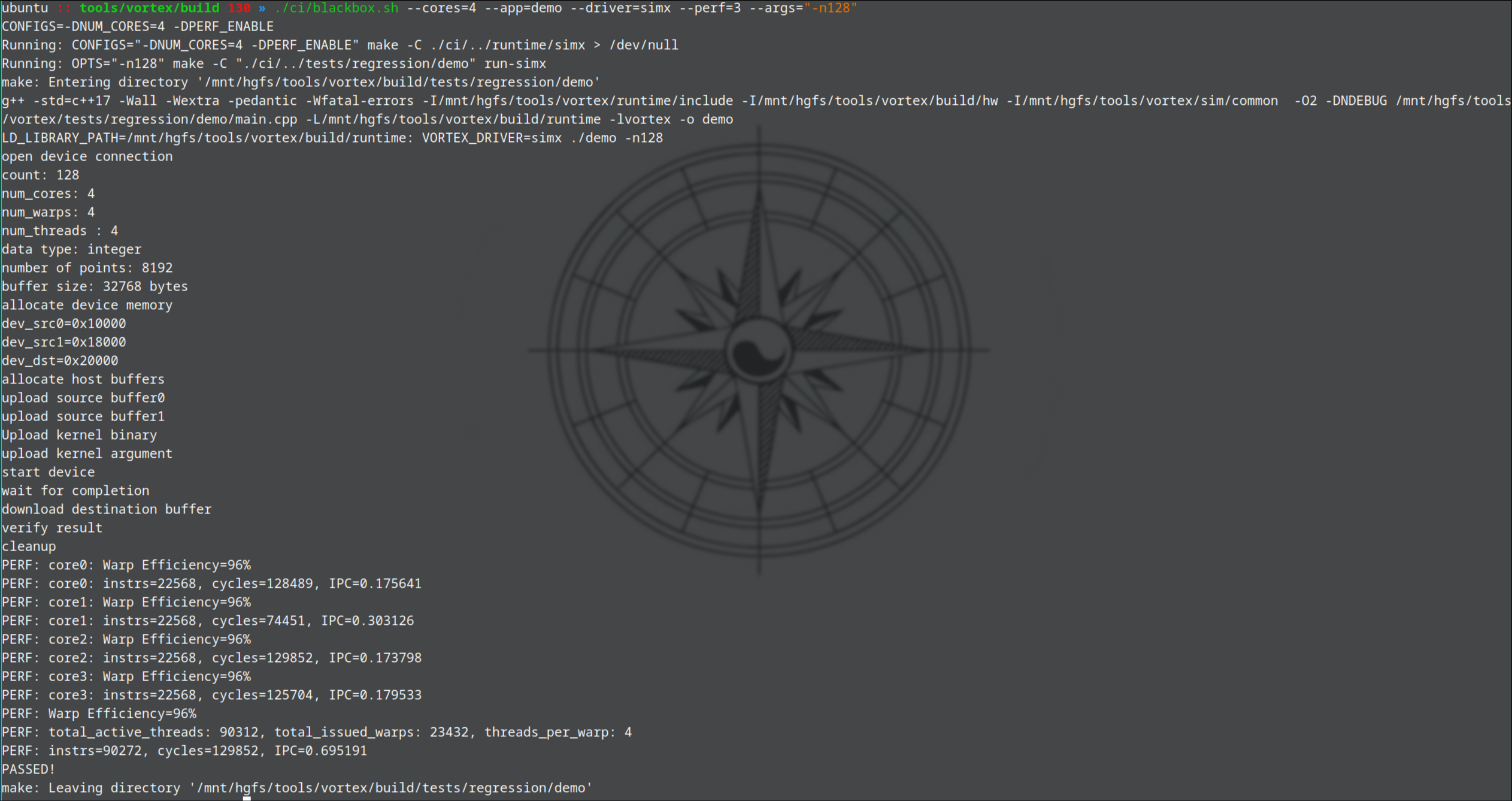
运行测试
|
|